
ASR之Transformer
Transformer是Google在这篇论文中提到
Attention Is All You Need
先上它的总图
![]()
下面对图中每一个组件的简单描述,
| 组件 | 描述 |
|---|---|
| Add & Norm | 残差连接和Layer Norm,关于这2个东西后面有详细的介绍 |
| Feed Forward | point-wised的前馈神经网络,就是都个线性层以ReLu为激活函数 |
| Muti-head Attention | 多头的Self Attention |
| Positional Encoding | 做位置信息编码 |
| Input Embedding | 把输入表示为一个vector |
| Out Embedding | 把Encoder的输出表示为一个vector |
| Masked Multi-Head Attention | 多头的Self Attention,不过在Self Attention的时候只考虑前面(左边)的向量 |
| Linear | 线性变换,实际就是乘以一个矩阵 |
| Softmax | 将向量中各维转换成概率 |
图中可以看到N x ,代表N个那样的块(Block)。
这里说一下Input/ouput embedding,在Google团队发表这个论文的时候,它们的使用场景是机器翻译,输入是一段变长的句子,输出一段变长的句子,而网络层输入设计的时候就好定好是多长,因此需要变长的句子变成定长的vector。可以使用word2vec, glove,fasttext做这个事情,或者直接嵌入一层-embedding layer(当然这个需要train)。而在ASR的任务中,我们可以输入定长的vector,比如每次20,30个mfcc。
Transformer还是属于我们Sequence to Sequence的模型。因此我们还可以使用下面的图表示,
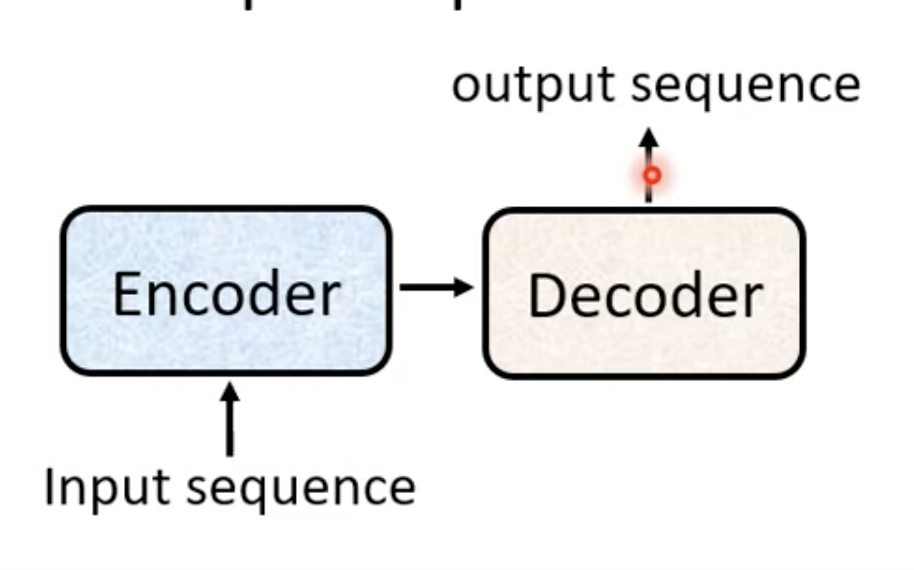
Transformer总图中的左边部分我们可以放到Encoder里面,右边部分可以放到Decoder里面。
Encoder
它的作用就是把输入序列表达成另外一种抽象表示,使用Self Attention后接一个Fully Connected Network。
Encoder我们用下面的简单的形式表示出来
![]()
输入到Block,一番操作后,它的输出再次输入另外一个Block,经过N个Block之后,得到一组向量。那么这个Block里面的东西怎么理解呢。
![]()
4个vector输入之后,首先经过self attention之后得到4个向量,我们把最左边那个输出标为a,这里b是输入vector的最左边一个,然后a和b相加,这种操作称作残差连接(residual connection),紧跟着做layer normalization。有篇论文专门讨论Layer Normalization。Layer Norm做的事情,输入一个vector,输出一个vector,首先计算输入vector的各纬的均值(m)和标准差(σ),然后使用下面的公式,
Xi' = ( Xi - m )/ σ
得到新的vector d,接下来将d输入到fully connected network得到vector f,然后d和f再做残差连接,再做layer norm得到最终这个Block的输出。
这样我们就把Encoder里面大部分的内容说完了,剩下一个Positional Encoding,这是因为在做完self attention之后,丢掉原有向量序列的位置信息,而这些对最后输出有直接的影响,比如输入语音信号的顺序对最后识别出来的结果的影响。Positional Encoding之后得到1个或者2个vector,然后把它们cancat在input/output embedding的vector。例如下面利用下面的公式将2n+1位置的使用cosine函数操作一遍,2n位置的使用sin函数操作一遍,分别得到1个vecotr,共2个vector拼接embedding的vector上面。
![]()
在Attention Is All You Need的Positional Encoding部分有详细介绍,包括上面的公式。
下面是另外一篇文章详细介绍Positional Encoding,附有代码,
A Gentle Introduction to Positional Encoding In Transformer Models, Part 1
另外整个Transformer中用到的self attention是Multi-Head的Self Attention,这部分在ASR之Self Attention文章有解释。
Decoder
总的来说Decoder做的是下面的事情,
![]()
将Encoder输出的一组vector输入到Decoder,另外还有另外一个输入,就是上一个输出,对于第一输出,前面没有输出过什么,我们输入一个特殊的token,BEGIN,表示一句话的开始。你也可以定义成别的什么,只要你知道代表开始就可以了,Decoder输出向量之后,为了得到这个向量对应我们的token集合中那个几率最高,需要做一次softmax,之后直接输出对应的token。
对于什么时候结束,和ASR之Listen Attention Spell介绍的一样,输出一个表示结束的token,比如这里我们定义一个END。
![]()
Autogressive Decoder和None Autogressive Decoder
在继续介绍Decoder的细节之前,插一个新东西 – Autogressive Decoder和None Autogressive Decoder。
![]()
上面介绍Decode过程,下面输出的token依赖前一个输出,下一个输出依赖当前token,一次类推,像这样的Decoder,叫做Autogressive Decoder。和Autogressive Decoder相对应的None Autogressive Decoder,不依赖前一个输入,给Encoder的输出向量和一推BEGIN,也就是把Autogressive Decoder依赖前一个输出的地方,把依赖直接换成固定的BEGIN。这样做的好处是,它不是顺序进行的,因此可以进行并行计算。不过这里有个问题,在Autogressive Decoder里面是通过输入EOS来达到输出结束效果,在None Autogressive Decoder怎么知道什么时候结束呢?有2个可行的方法,
1. 让网络自己学习
2. 一个固定大小的vector,让网络学习在那个位置输出END
在第一种办法中,我们加另外一个网络,比如RNN,它的输出是一个整数,代表输出序列的长度。第二办法,设定一个固定大小的vector,比如我们知道所有的输入对应的输出不可能输出超过200的token,就定vector的size是200,网络根据输入,自己知道在什么地方输出END,vector中END之后的输出就可以忽略。
None Autogressive Decoder的performance往往没有Autogressive Decoder好,其实这是不言而喻的,因为它没有考虑前一个输入。
Decoder里面的第一个组件用到的不是普通的Self Attention,而是Masked Self Attention。普通的Self Attention是会考虑左右所有的vector,如下图,
![]()
而Masked Self Attention,它是只考虑它左边的vector,
![]()
那为什么要做mask呢?这是因为Decoder里面的要用的输入一个一个得到,而在Encoder里面是一次将一组vector同时输入进去。所以虽然上图我们把4个vector都画在上面,但是比如在计算a2的时候好,后面的a3和a4是不存在的,所以计算self attention,就只能使用a1,a2了。其实可以说是不是不要考虑,而是没有办法考虑,因为看不到。
从总图上面可以看到Encoder的输出作为Decoder的里面的Multi-Head Attention,其实这边是Cross Attention,它实际操作如下,
![]()
它的q来自Decoder里面的向量,而k和v来自右边的Encoder里面。不过我个人觉得没有什么特别的地方,因为既然这个Encoder输出已然作为Decoder的输入了,那就当做Decoder里面的vector,就没有Cross这层含义,也就不用称作什么Cross Attention了。
Training
上面我们描述的大部分内容是在已经有了model之后怎么做识别的,下面说一下怎么train这个model。
![]()
Ground truth是one hot的vector,Decoder输出的向量经过Softmax后得到一个n纬几率的vector的,然后计算它们的Cross Entropy,训练的目标就是最小化这个CE的值。
在Decode的时候,当前Decoder的输出要依赖Encoder的输出和Decoder上一个的输出,如果在Training的时候,我们也只做么做的话,如果上一个的输出的错误的,这会造成Error Propagation,造成错误的传递,后面的训练全部白费,为了解决解决这个问题,Training的时候不使用上一个输出作为当前的输入,而是采用正确的输出- ground truth,我们管这种方法叫做Teacher Forcing。
可以看到Decode的时候和Train的时候有这种mismatch,就是训练的时候参照ground truth,而解码的时候参照前一个输出,如果decoder的前一个错误,那么那个被训练成之后给对的输入才能产生正确输出的模型就会出问题-产生错误的输出,并且error propogate下去,我们管这种现象叫Exposure Bias。
关于Exposure Bias可以参看
Generalization in Generation: A closer look at Exposure Bias
Seq2seq Model and The Exposure Bias Problem
为了解决Exposure Bias的问题,有人提出了针对Transformer的Scheduled Sampling,
Scheduled Sampling for Transformers
Parallel Scheduled Sampling
最初的Scheduled Sampling论文
Scheduled Sampling for Sequence Prediction with Recurrent Neural Networks
想法就是在train decoder的时候,随机的选择两种输入中的一种,两种输入分别是
– ground truth
– 前一个输出
(我在想既然这样,要不要直接把对前一个输出的依赖去掉?)
在Google的Attention Is All You Need论文中Transformer他们使用在Machine Translate任务中,评估(Evaluation)的时候使用的BLEU score,在我们的ASR中任务我们采用ASR中常用的WER。关于BLEU,可以参看
Understanding the BLEU Score
本文的图片来自:
Attention Is All You Need
参考
Illustrated Guide to Transformers- Step by Step Explanation
The Illustrated Transformer
One Reply to “ASR之Transformer”