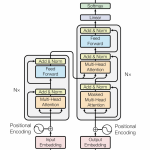
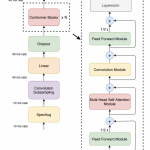
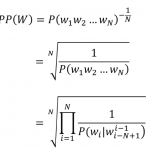ASR之Sequence to Sequence
什么是Sequence to Sequence
Sequence to Sequence可以使用下面的图表示,就是输入一个序列,经过Encoder,Decoder之后输出一个序列,
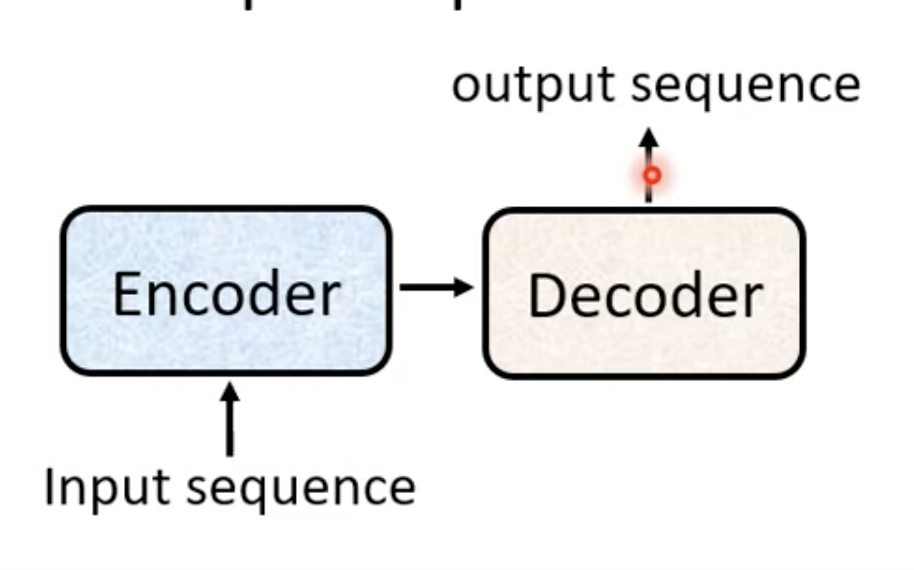
因此很多人也会直接把Sequence to Sequence模型叫做Encoder Decoder模型。
Sequence to Sequence在ASR
Sequence to Sequence用在ASR上面可以简单表示成下面的样子,
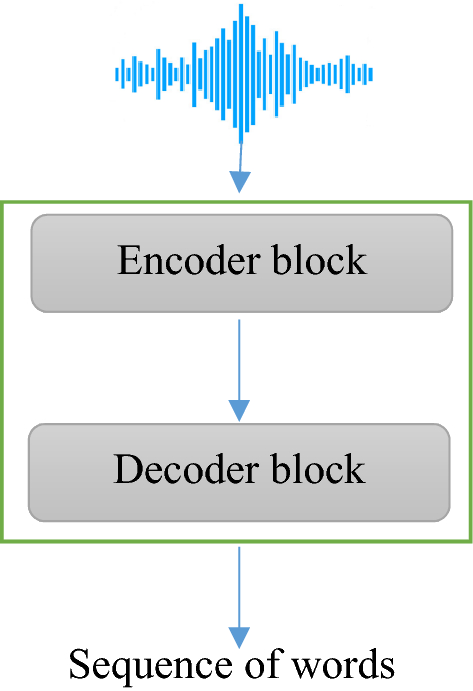
Sequence to Sequence的应用
那Sequence to Sequence可以做什么呢?
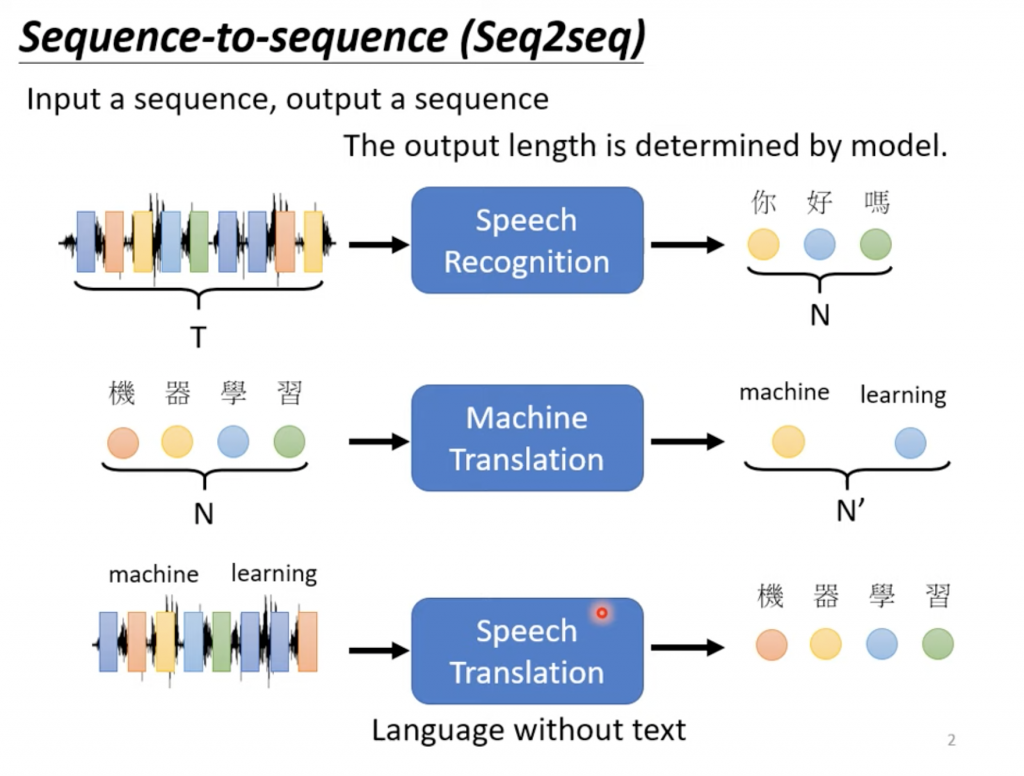
或者我们设计一个chat robot,给出一句话,它给出响应。
甚至有人可以用做Sequence to Sequence语法分析
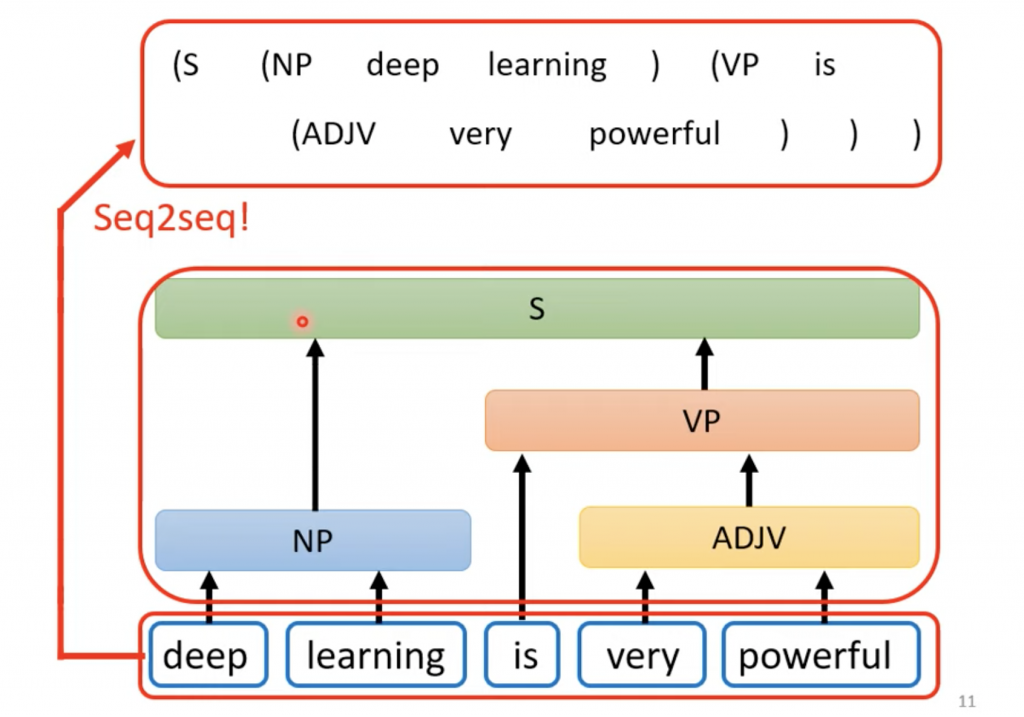
Oriol Vinyals等人就在2014使用Sequence to Sequence做了语法分析,参看下面的链接,
Grammar as a Foreign Language
很多问题我们都可以看成Sequence to Sequence的model,比如给一个文章,给出文章的摘要;给一段英文,给出中文的翻译;给出一段话,做情感分析。Sequence to Sequence的model可以看成QA的model,一个输入,问个问题(Question),模型给出答案(Answer)。
Sequence to Sequence的几种模型
在ASR的Sequence to sequence的模型有以下几种,
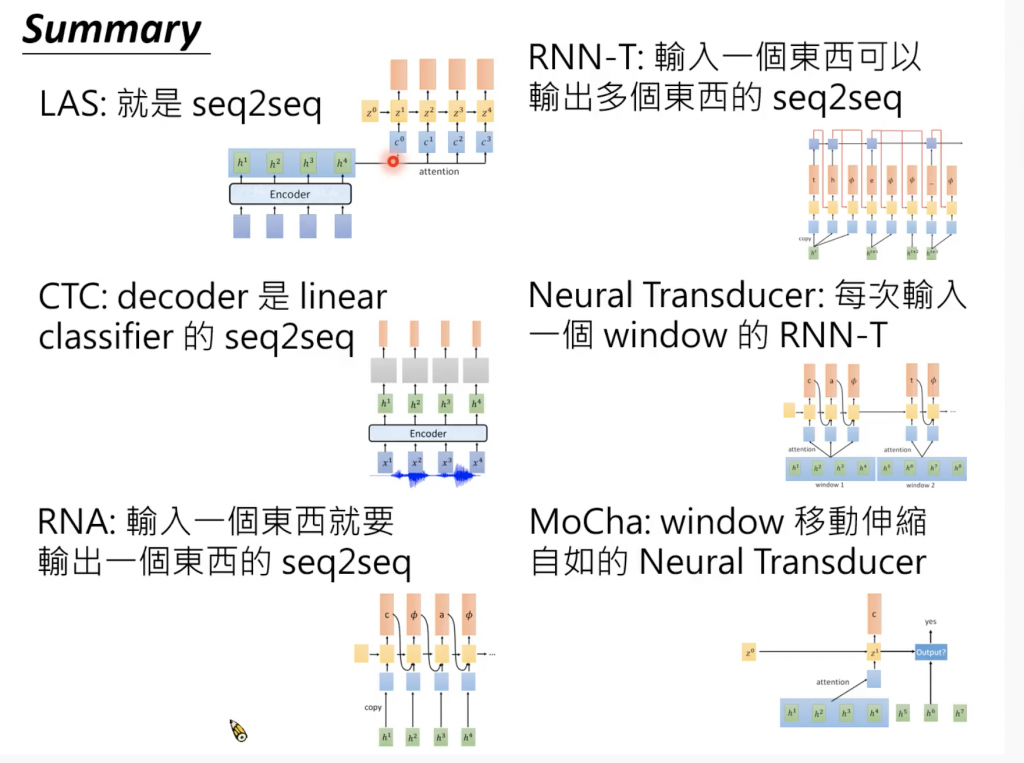
这几种模型在2019使用频率可以用下面图表示,
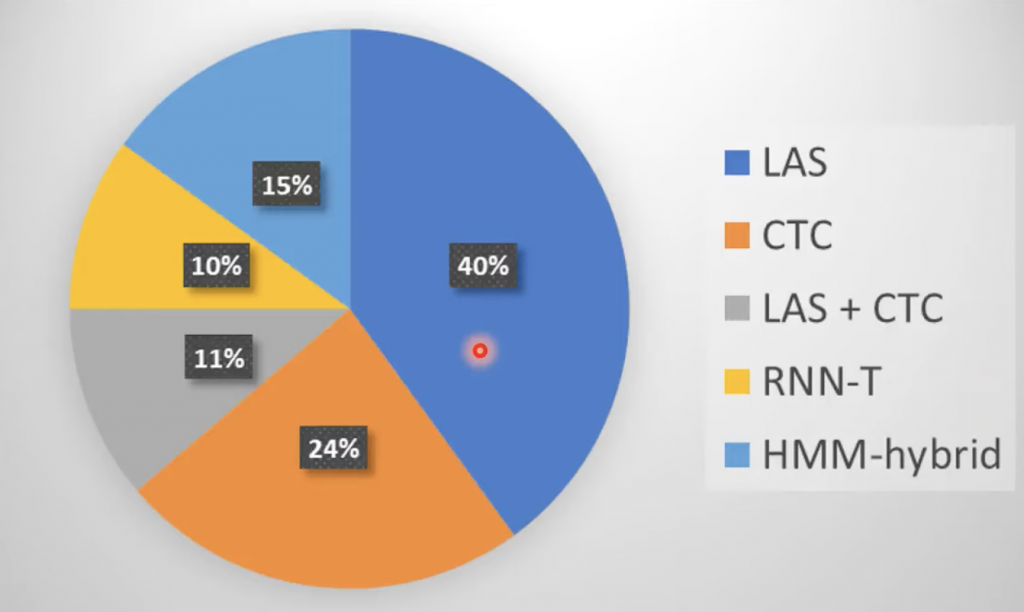
上图是基于统计INTERSPEECH的100篇论文得到的结果。
几种模型的介绍
下面是其中的几种模型的学习笔记
Listen Attention Spell
ASR之CTC
ASR之RNN-T
ASR之Self Attention
ASR之Transformer
Sequence to Sequence一些技巧
Train的技巧
- Copy Mechanism
在前面提到的chat bot里面,对于一些输入我们需要直接输出,而不是自己创造输入,比如
“我今天见了王金鑫老同学”
对了“王金鑫”我们就可以直接copy 过去
或者对了 文章摘要的任务,可以直接从里面copy一些过来,比如文章标题之类的。
有人就copy mechanism专门写了论文,
Incorporating Copying Mechanism in Sequence-to-Sequence Learning
- Guided Attention
我们强制一些规则,比如在TTS里面,我们强制,输入输出序列一一对齐。
Monotonic Attention
Locationware Attention
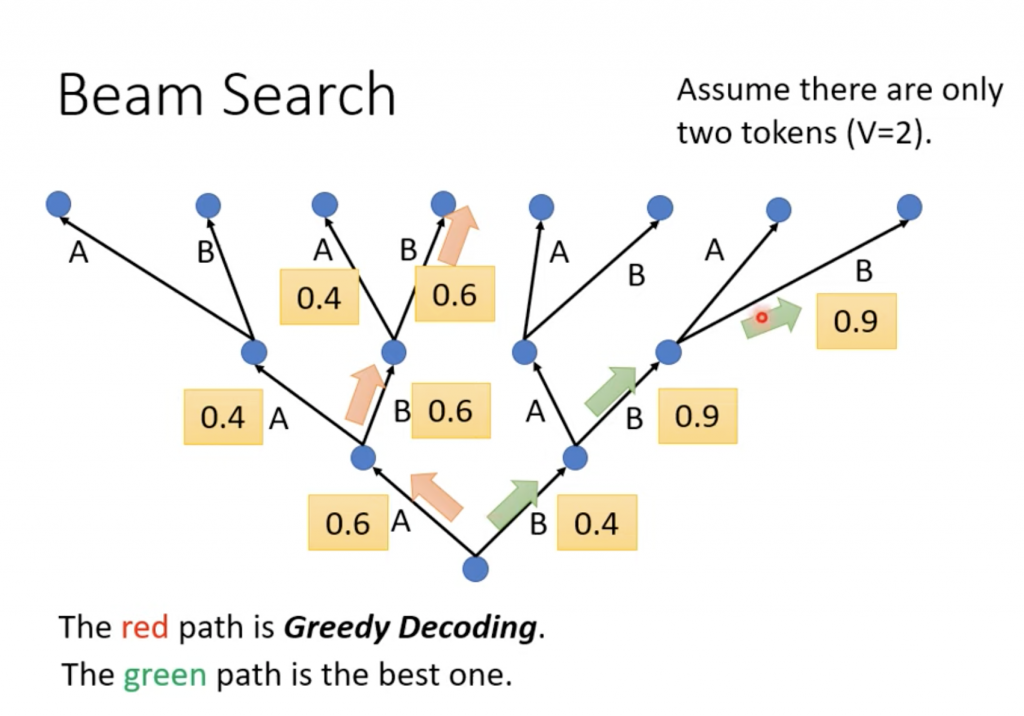
Beam Search
Decoder出来的东西我们一般都是做softmax之后得到distribution,里面就是每个token的几率,一般去几率最高的那个,但是从整个句子看,最高那个可能不是最好的,我们可以采用beam search的方法,就是去几个,比如头2个,每次都是头2个。最后还会发现可能一开始几率不是最高的那个反而是最好的结构。下面的图假设token集合中只有A和B两个token。