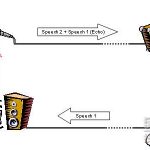
请参看:
http://blog.360converter.com/archives/34
本文的提到的混音是基于原始的,未经压缩的声音数据。
常用的混音算法有如下几种:
1. 音频数据直接线性叠加
C=A + B
这种方法极易产生溢出
2. 线性叠加后再做均值
C = (A + B)/2
3. 算法表达式如下
Z=A+B−AB256
.
Z=A+B−AB
256
.
C
= A + B – AB/[Maximum] // 这里的Maximum要根据声音数据的量化值,如果是8bit那么就是256,如果是16bit就是65536
4. 增加原始数据的位域比如32bit,然后进行2个语音波形的叠加,也就是直接线性叠加叠加,然后归一化到原来的位域范围。
前面3个算法中第2个效果比较好。
参考资料:
http://hi.baidu.com/%C7%A3%D0%EBde%D3%E3/blog/item/d101d8c3a0bdbf3de4dd3b5e.html
http://blog.csdn.net/kinghuangsheng/article/details/7302240
http://www.vttoth.com/CMS/index.php/technical-notes/68
版权所有,禁止转载. 如需转载,请先征得博主的同意,并且表明文章出处,否则按侵权处理.