RNN LSTM GRU
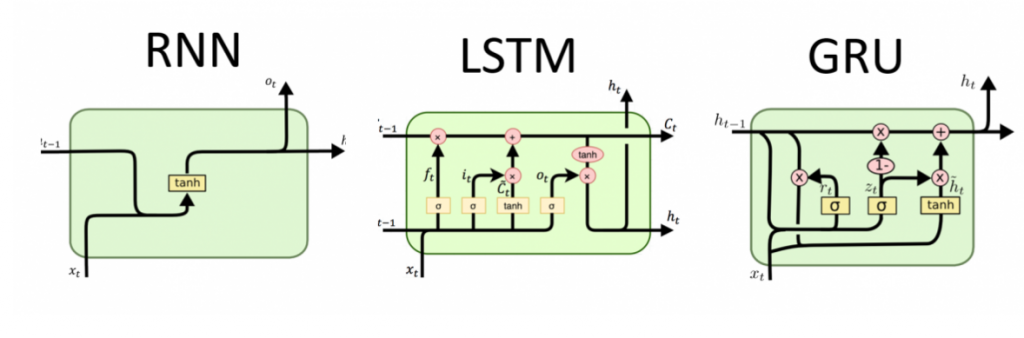
为什么要把三个列在一起,因为它们之间从左到右进阶的关系,最开始大家用RNN,发现问题,提出方案就有了LSTM,同样方式就有了GRU。
RNN在时间跨度够长,就会有一个梯度消失,或者梯度爆炸的问题,因此人们在加入了一个遗忘门的概念,目的是就是定期去删除以往的记录。在LSTM中由于输入门,输出门和遗忘门,太过复杂,复杂意味着计算量大,训练难度的增加,因此有人提出了新的模型GRU,把输… 更多... “RNN LSTM GRU”

IT夜班车
关于机器学习,深度学习和神经网络
为什么要把三个列在一起,因为它们之间从左到右进阶的关系,最开始大家用RNN,发现问题,提出方案就有了LSTM,同样方式就有了GRU。
RNN在时间跨度够长,就会有一个梯度消失,或者梯度爆炸的问题,因此人们在加入了一个遗忘门的概念,目的是就是定期去删除以往的记录。在LSTM中由于输入门,输出门和遗忘门,太过复杂,复杂意味着计算量大,训练难度的增加,因此有人提出了新的模型GRU,把输… 更多... “RNN LSTM GRU”
下面做一个简单的比较,顺便跟Tensorflow比较一下,
| Keras | PyTorch | TensorFlow | |
| API | High | Low | High and Low |
| 架构(学习难度) | Simple, concise, readable | Complex, less readable | Not easy to use |
| 调试 | Simple network, so debugging is not often needed | Goo |
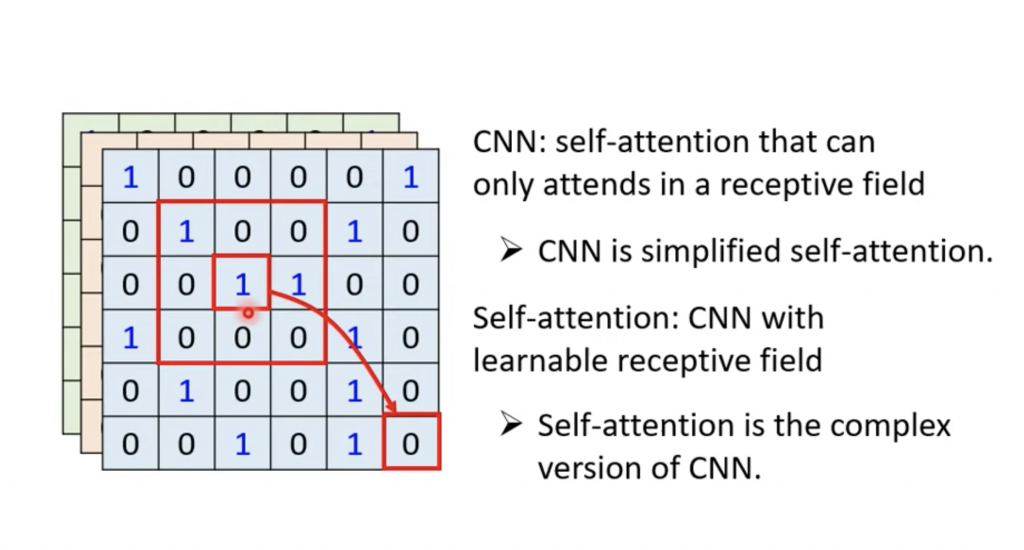
Self Attention和CNN,RNN有很多的相似之处。这篇文章大致说一下有什么的相似之处,关于细节需要研读下面提到的相关论文。
CNN是self attention的子集。

主流移动端深度学习框架大盘点
简书作者 dangbo 在《移动端深度学习展望》一文中对现阶段的移动端深度学习做了相关展望。作者认为,现阶段的移动端 APP 主要通过以下两种模式来使用深度学习:
online 方式:移动端做初步预处理,把数据传到服务器执行深度学习模型,优点是这个方式部署相对简单,将现成的框架(Caffe,Theano,MXNet,Torch) 做下封装就可以直接拿来用,服务器性能大, 能够处理比较大… 更多... “主流移动端深度学习框架大盘点”
回归在数学上来说是给定一个点集,能够用一条曲线去拟合之,如果这个曲线是一条直线,那就被称为线性回归,如果曲线是一条二次曲线,就被称为二次回归,回归还有很多的变种,如locally weighted回归,logistic回归,等等,这个将在后面去讲。
用一个很简单的例子来说明回归,这个例子来自很多的地方,也在很多的open source的软件中看到,比如说weka。大概就是,做一个房屋价值的评估系统,一个… 更多... “机器学习中的回归(regression)和梯度下降(gradient descent)”
我打算写一系列的博客来一点点介绍人工智能,以及在背后支持人工智能的机器学习和深度学习
所有的东西都是根据个人搜集和按照自己的理解(当时的理解)所写,因此难免会有错误,不过
随着学习的深入,我会不断的更新和纠正。
为什么是浅入门,因为本人所学的东西感觉只是这个领域的皮毛而已,所以还谈不上入门。
先说说这3者的关系,用一张图来描述
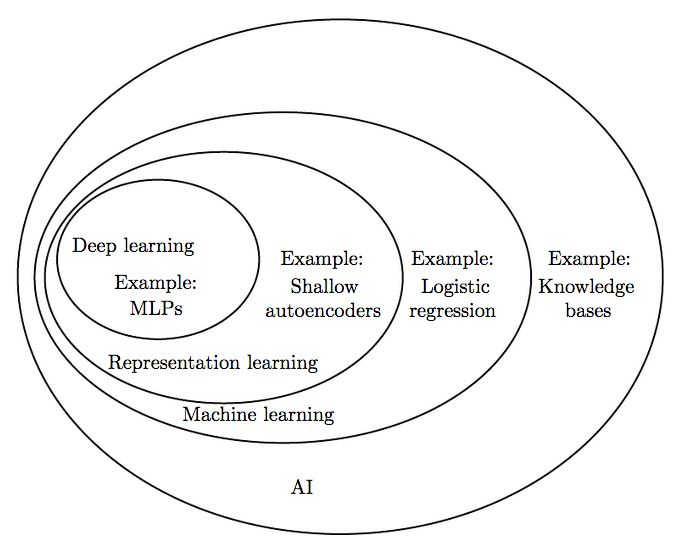
从上图可以看出,AI(人工智能)涵盖的范围最大,接下来是机器学习(… 更多... “深度学习浅入门”
在大部分机器学习课程中,回归算法都是介绍的第一个算法。原因有两个:一.回归算法比较简单,介绍它可以让人平滑地从统计学迁移到机器学习中。二.回归算法是后面若干强大算法的基石,如果不理解回归算法,无法学习那些强大的算法。回归算法有两个重要的子类:即线性回归和逻辑回归。
线性回归就是我们前面说过的房价求解问题。如何拟合出一条直线最佳匹配我所… 更多... “机器学习的算法简单描述”