Kaldi之Lattice
在Decode时候,使用Viterbi算法可以得到最优的一条路径,但是往往它可能不是最好的,因此我们采用Beam Search得到一个几个路径,我们给定一个范围(Kaldi的命令参数使用的时候 –beam),距离最优路径一定范围的都留下来,于是会得到N best的结果

我们可以采用保存所有它走的路径,包括状态,ilabel,olabel,第几帧等信息。
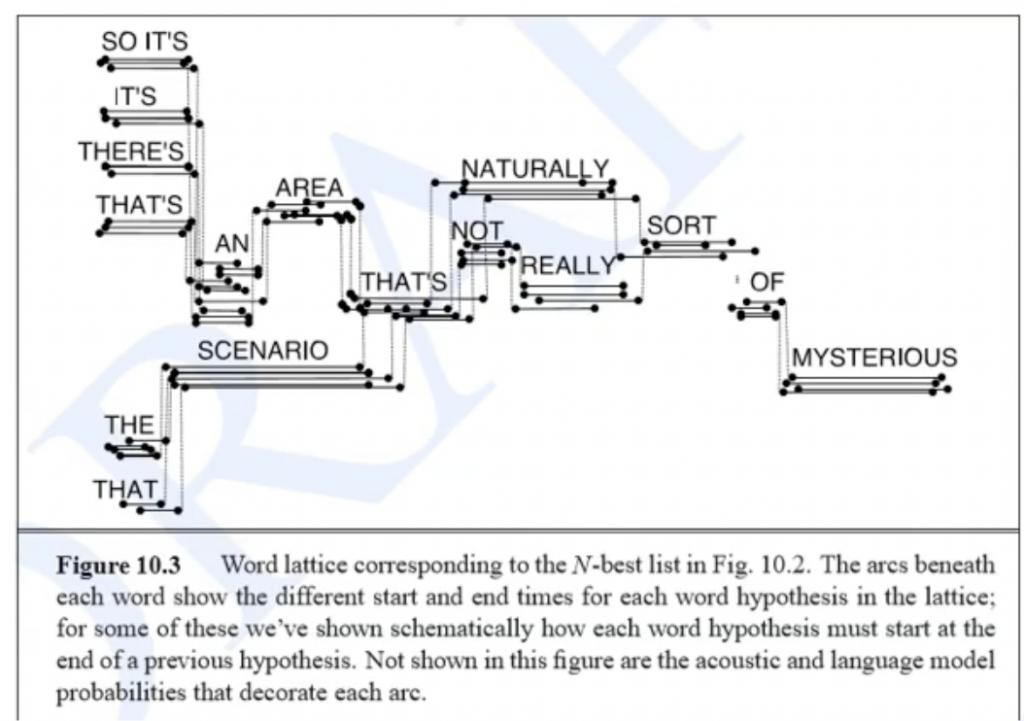
那N best的时… 更多... “Kaldi之Lattice”

IT夜班车
在Decode时候,使用Viterbi算法可以得到最优的一条路径,但是往往它可能不是最好的,因此我们采用Beam Search得到一个几个路径,我们给定一个范围(Kaldi的命令参数使用的时候 –beam),距离最优路径一定范围的都留下来,于是会得到N best的结果
我们可以采用保存所有它走的路径,包括状态,ilabel,olabel,第几帧等信息。
那N best的时… 更多... “Kaldi之Lattice”
WFST : Weighted Finite State Transducer
FSA : Finite State Acceptor
用来判断一个字符串能不能被接受。
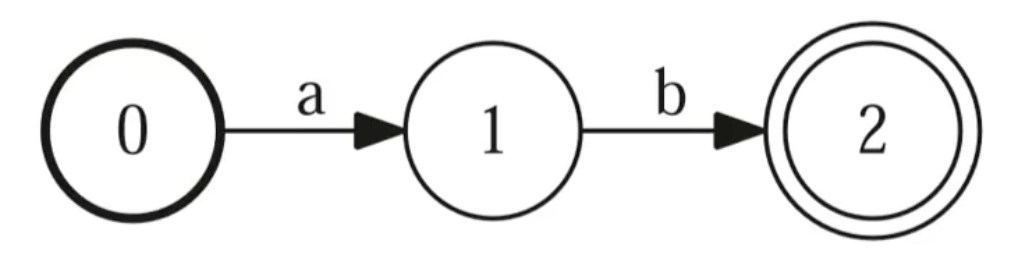
WFSA : Weighted Finite State Acceptor
用来判断一个字符串能不能被接受,并且给出能接受的概率。
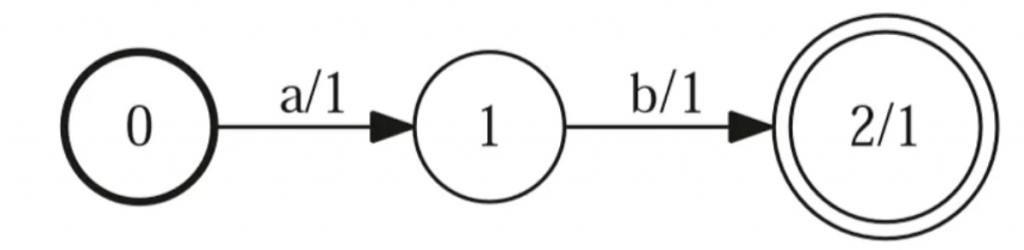
WFST : Weighted Finite State Transducer
用来把一个序列转换为另外一个序列,… 更多... “Kaldi之WFST”
区分性训练可以简单地理解为使得正确的更正确,错误的更错误。区分性训练之后的ASR识别效果可以有10-20%的提升。
区分性训练是一类训练准则的总称,包括
1. MMI - Maximum Mutual Information
2. bMMI - boosted Maximum Mutual Information
3. MPE - Minimize Phonime Error
4. sMBR - state-level Mini
里面共有三种格式 csl, int, txt ,其实内容都是一样的,
align_lexicon
表示对齐文件,是由lexiconp.txt的第一列第三列提取出来生成
context_indep
非正常音素集合,包含(静音(SIL),口语噪声(SPN),非口语噪声(NSN)和笑声(LAU)
silence
静音音素
nonsilence
正常音素 可以认为和上面的silence是… 更多... “Kaldi的Phones文件夹下面的文件介绍”
Kaldi中的topo结构,在每个样例中是以topo文件表示,在代码中是由HmmTopology这个类表示,拓扑结构中的参数的更新会在TransitionModel这个类体现出来。
下面是Kaldi中yesno样例下面的topo文件,文件位置:
egs/yesno/s5/data/lang/topo
这个文件是由utils/gen_topo.pl生成,而这个脚本是在utils/… 更多... “Kaldi中的topo结构”
CMVN是Cepstral Mean Variance Normalization的缩写,中文直译为倒谱均值方差归一化。这里插一句Cepstral这个词是就是谱(spectrum)这个单词的前4个字母倒过来。
在把MFCC送到解码器之前,kaldi会计算一个CMVN。为什么计算CMVN,下面给出一个理由
实际情况下,受不同麦克风及音频通道的影响,会导致相同音素的特征差别比较大… 更多... “Kaldi中为什么要计算CMVN”
kaldi官方提供了所有工具的说明
https://www.kaldi-asr.org/doc/tools.html
这里只是列出查看文件的工具.
Data from kaldiOfficial Documents。
Reproduced indicate the source.
copy-feats Can be used to change the format of feature dat… 更多... “Kaldi查看文件的工具”
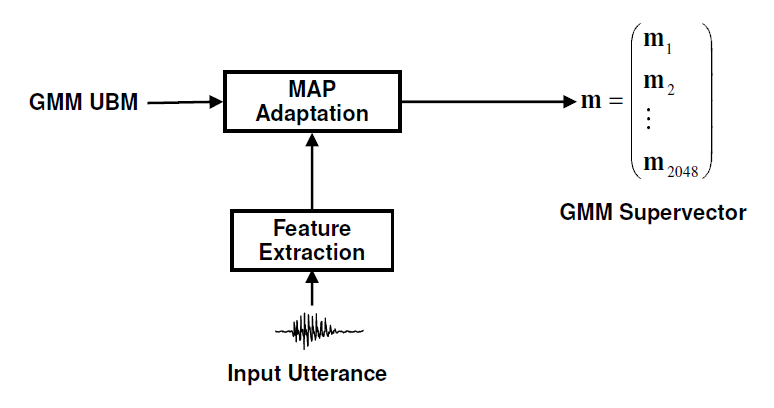
使用MAP adaptation对UBM的高斯进行线性插值,获得speaker相关的GMM… 更多... “声学特征iVector及其Kaldi实现”
数据堂200h中文开源数据,用于语音识别 LM+MFCC+Mono+Triphone(tri1:deltas;tri2:delta+delta-delta;tri3a:lda+mllt)+fMLLR+SAT+TDNN
openslr33数据 ,声纹识别 MFCC+UBM+PLDA
openslr33… 更多... “Kaldi的egs下通用样例解释”
utils/subset_data_dir.sh
分割数据,用于建立初始小模型,而后一步一步扩充
steps/train_mono.sh
单音素模型训练
steps/align.sh, steps/align_si.sh, steps/align_fmllr.sh
强制对齐
steps/train_sat.sh
说话人自适应,一般之后跟fmllr,第一个sat前用si或者fmllr,s… 更多... “Kaldi中每个脚本的简单解释”