ASR之Conformer
Conformer是Transformer的变种,在encoder里面加入了CNN模块。
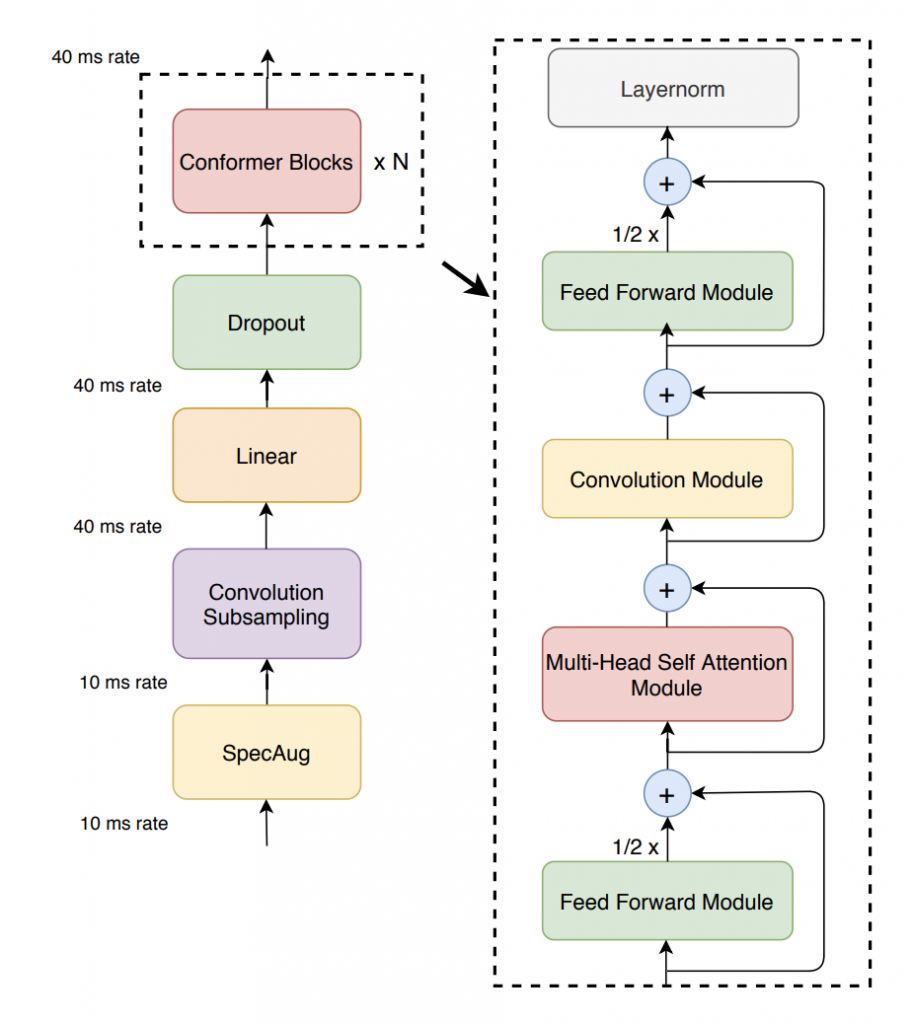
跟Transformer比较,主要是加了Convolution Module,除此之外,feed forward变成了2个,残差层是1/2. 去掉了Transformer的Position Encoding层,Transformer中加入这一层主要是Self Attention的机制导致丢失了输… 更多... “ASR之Conformer”

IT夜班车
Conformer是Transformer的变种,在encoder里面加入了CNN模块。
跟Transformer比较,主要是加了Convolution Module,除此之外,feed forward变成了2个,残差层是1/2. 去掉了Transformer的Position Encoding层,Transformer中加入这一层主要是Self Attention的机制导致丢失了输… 更多... “ASR之Conformer”
BPE代表Byte Pairing Encoding,对于英文来说,就是一个或者几个字符的组合。在Kaldi中,word是被表示为,或者分解为phone,怎么做呢?就是根据对应语言的字典模型-lexicon。对于大多数语言,我们都可以采用CMU免费提供的Lexicon。但是对于小语种,那么可能就没有对应的lexicon可以用,那么可以采用BPE。
下面举个例子,假设我们要编码aaabdaa… 更多... “ASR之BPE”
待补充…
如何评价一个语言模型的好坏,
– 实际测试
– 困惑度(perlexity)
实际测试就是把训练的好的语言直接使用ASR的解码中,查看准确率。这个方法准确度高,但是效率低,因为我们把一个语音模型的评测问题变成了ASR的解码问题。
除了实际测试,还可以直接计算困惑度。就是把几个句子连起来变成一个很长的句子,然后使用… 更多... “ASR之语言模型”
在Decode时候,使用Viterbi算法可以得到最优的一条路径,但是往往它可能不是最好的,因此我们采用Beam Search得到一个几个路径,我们给定一个范围(Kaldi的命令参数使用的时候 –beam),距离最优路径一定范围的都留下来,于是会得到N best的结果

我们可以采用保存所有它走的路径,包括状态,ilabel,olabel,第几帧等信息。
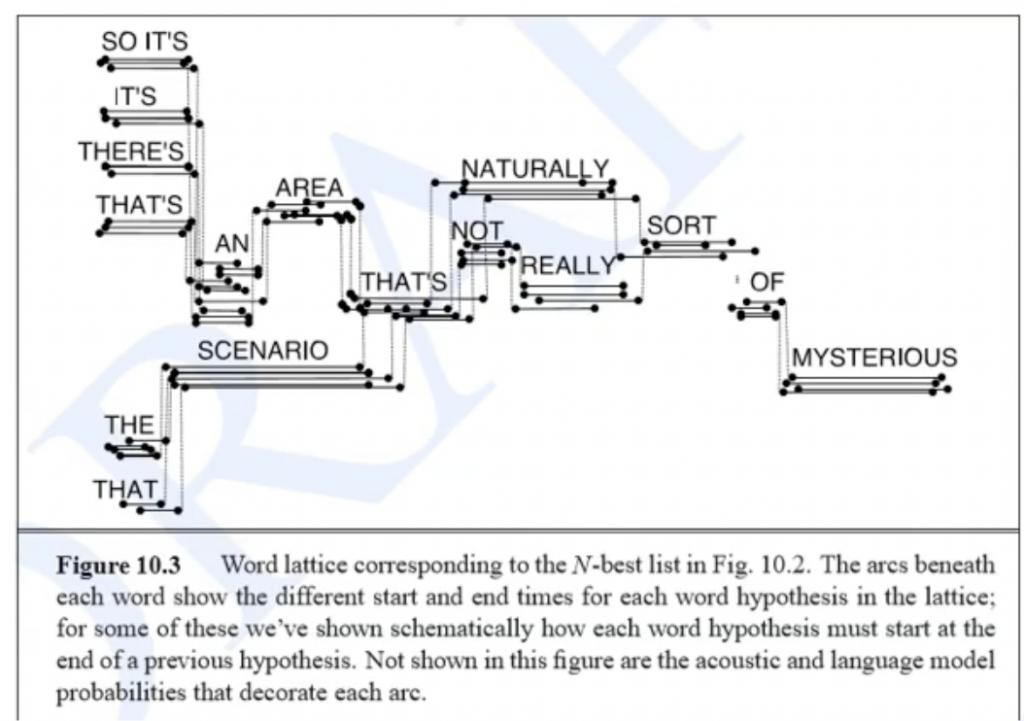
那N best的时… 更多... “Kaldi之Lattice”
WFST : Weighted Finite State Transducer
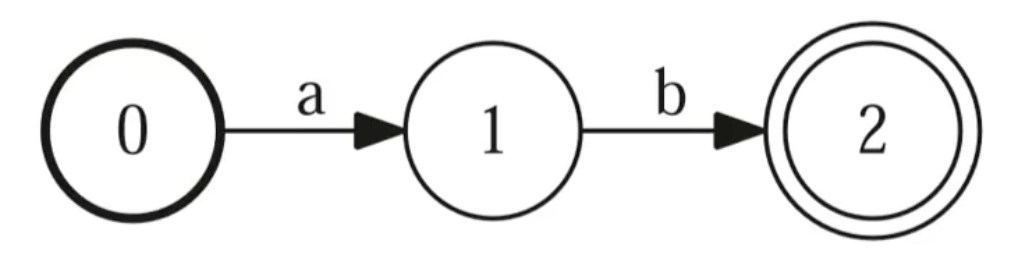
FSA : Finite State Acceptor
用来判断一个字符串能不能被接受。
WFSA : Weighted Finite State Acceptor
用来判断一个字符串能不能被接受,并且给出能接受的概率。
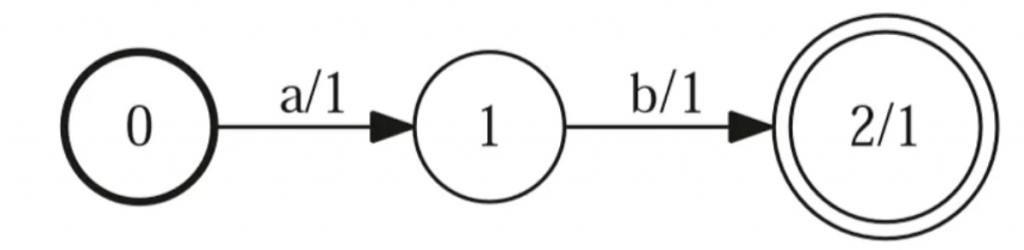
WFST : Weighted Finite State Transducer
用来把一个序列转换为另外一个序列,… 更多... “Kaldi之WFST”
2022年8月1号:Self Supervised Learning的框架,参数非常多,比如典型的BERT,参数个数为340M,训练需要的数据量巨大(这个使用类似GigaSpeech或者MultiSpeech可以解决),需要很多GPU,或者需要直接跑在TPU上,训练需要很长的时间才来完成(具体的例子参看本文后面附的视频的44分钟部分)。这里说这个,是… 更多... “ASR之Self Supervised Learning”
区分性训练可以简单地理解为使得正确的更正确,错误的更错误。区分性训练之后的ASR识别效果可以有10-20%的提升。
区分性训练是一类训练准则的总称,包括
1. MMI - Maximum Mutual Information
2. bMMI - boosted Maximum Mutual Information
3. MPE - Minimize Phonime Error
4. sMBR - state-level MiniTransformer是Google在这篇论文中提到
Attention Is All You Need
先上它的总图
![]()
下面对图中每一个组件的简单描述,
| 组件 | 描述 |
|---|---|
| Add & Norm | 残差连接和Layer Norm,关于这2个东西后面有详细的介绍 |
| Feed Forward | point-wised的前馈神经网络,就是都个线性层以ReLu为激活函数 |
| Muti-head Attention | 多头的S |
这里的声学模型可以时候GMM-HMM或者DNN-HMM。
在HMM的模型中,我们隐状态和观测状态,比如下面的例子,
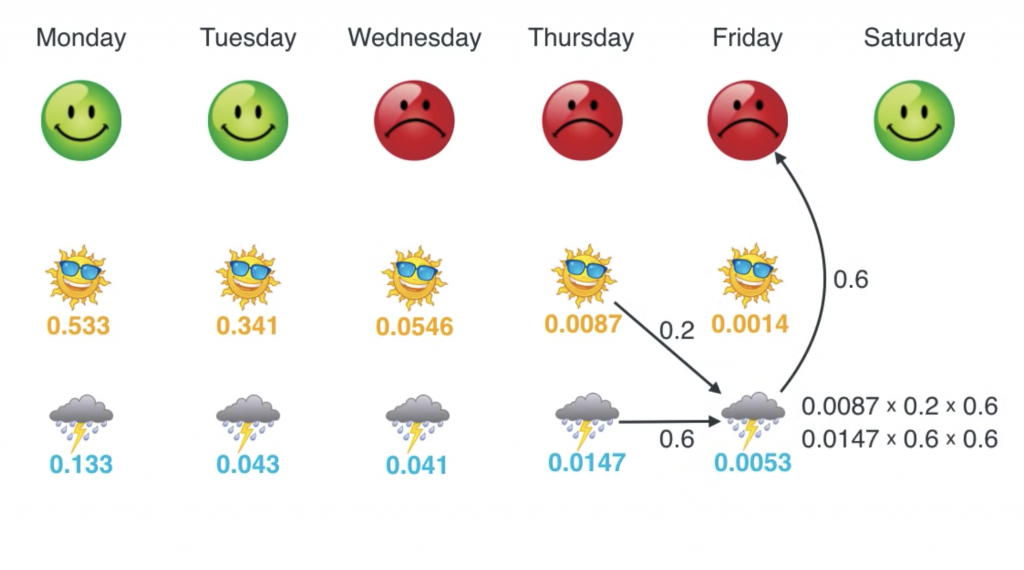
表情为观测,天气为隐状态,我们是在知道表情的情况下,使用viterbi算法去推测天气。
viterbi算法涉及3个概率,初始概率,转移概率,观测概率。上面的例子中就是给定天气的情况,观测到某个心情的概率。所以这里的观测状态很明确,就是心情。
所以输入 一些列的心情,输… 更多... “ASR之声学模型的观测状态”
self attention和Listen Attention Spell笔记中提到的Attention非常相似,不过它作的点乘z不再是有外部提供,而是就是自身,另外多了V向量,在LAS的Attention种V就是向量h自身。
self attention是Google发表的Attention is All you need这篇论文中提到,其实论文主要的说的Transformer,… 更多... “ASR之Self Attention”