ASR之Self Supervised Learning
2022年8月1号:Self Supervised Learning的框架,参数非常多,比如典型的BERT,参数个数为340M,训练需要的数据量巨大(这个使用类似GigaSpeech或者MultiSpeech可以解决),需要很多GPU,或者需要直接跑在TPU上,训练需要很长的时间才来完成(具体的例子参看本文后面附的视频的44分钟部分)。这里说这个,是… 更多... “ASR之Self Supervised Learning”

IT夜班车
2022年8月1号:Self Supervised Learning的框架,参数非常多,比如典型的BERT,参数个数为340M,训练需要的数据量巨大(这个使用类似GigaSpeech或者MultiSpeech可以解决),需要很多GPU,或者需要直接跑在TPU上,训练需要很长的时间才来完成(具体的例子参看本文后面附的视频的44分钟部分)。这里说这个,是… 更多... “ASR之Self Supervised Learning”
区分性训练可以简单地理解为使得正确的更正确,错误的更错误。区分性训练之后的ASR识别效果可以有10-20%的提升。
区分性训练是一类训练准则的总称,包括
1. MMI - Maximum Mutual Information
2. bMMI - boosted Maximum Mutual Information
3. MPE - Minimize Phonime Error
4. sMBR - state-level MiniTransformer是Google在这篇论文中提到
Attention Is All You Need
先上它的总图
![]()
下面对图中每一个组件的简单描述,
| 组件 | 描述 |
|---|---|
| Add & Norm | 残差连接和Layer Norm,关于这2个东西后面有详细的介绍 |
| Feed Forward | point-wised的前馈神经网络,就是都个线性层以ReLu为激活函数 |
| Muti-head Attention | 多头的S |
下面做一个简单的比较,顺便跟Tensorflow比较一下,
| Keras | PyTorch | TensorFlow | |
| API | High | Low | High and Low |
| 架构(学习难度) | Simple, concise, readable | Complex, less readable | Not easy to use |
| 调试 | Simple network, so debugging is not often needed | Goo |
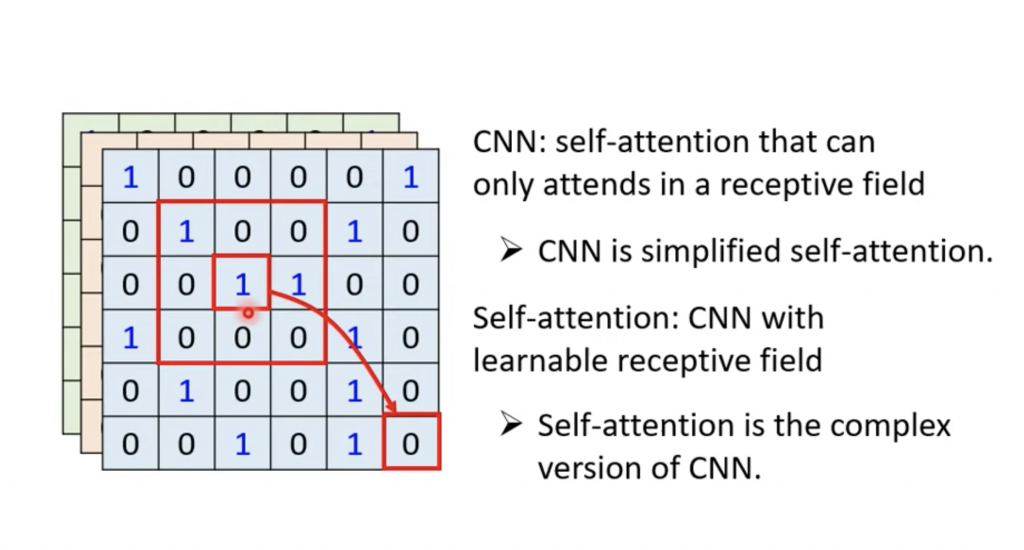
Self Attention和CNN,RNN有很多的相似之处。这篇文章大致说一下有什么的相似之处,关于细节需要研读下面提到的相关论文。
CNN是self attention的子集。

这里的声学模型可以时候GMM-HMM或者DNN-HMM。
在HMM的模型中,我们隐状态和观测状态,比如下面的例子,
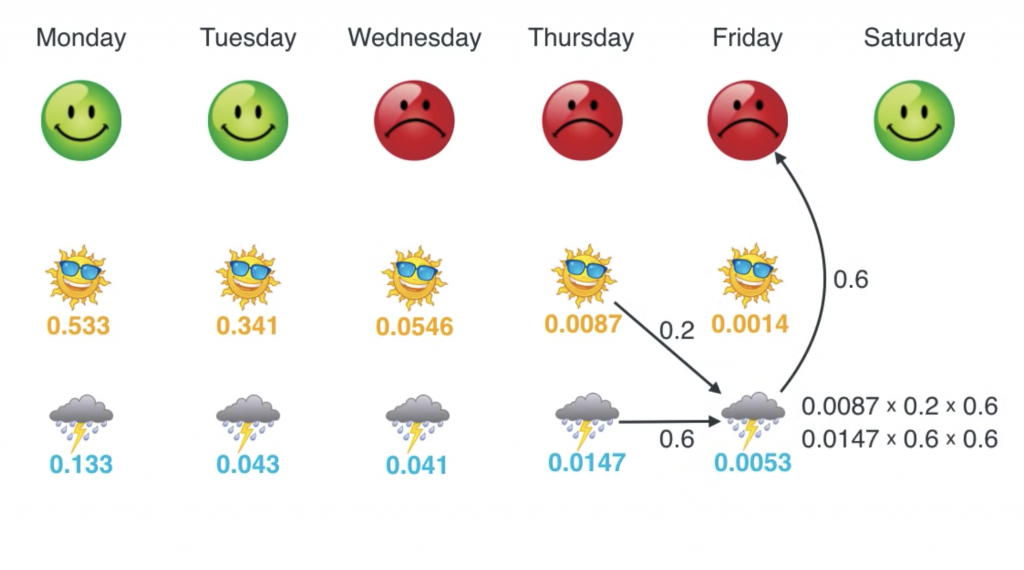
表情为观测,天气为隐状态,我们是在知道表情的情况下,使用viterbi算法去推测天气。
viterbi算法涉及3个概率,初始概率,转移概率,观测概率。上面的例子中就是给定天气的情况,观测到某个心情的概率。所以这里的观测状态很明确,就是心情。
所以输入 一些列的心情,输… 更多... “ASR之声学模型的观测状态”
self attention和Listen Attention Spell笔记中提到的Attention非常相似,不过它作的点乘z不再是有外部提供,而是就是自身,另外多了V向量,在LAS的Attention种V就是向量h自身。
self attention是Google发表的Attention is All you need这篇论文中提到,其实论文主要的说的Transformer,… 更多... “ASR之Self Attention”
Sequence to Sequence可以使用下面的图表示,就是输入一个序列,经过Encoder,Decoder之后输出一个序列,
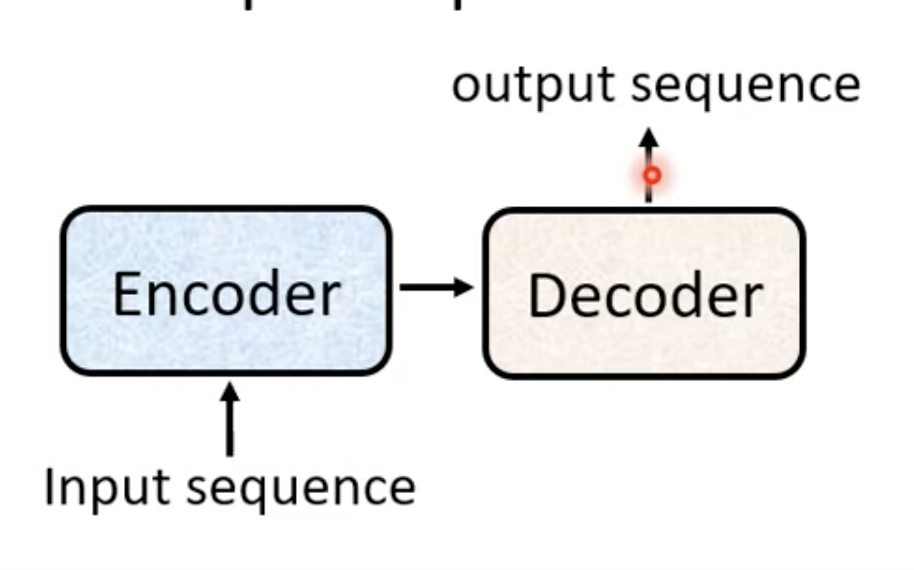
因此很多人也会直接把Sequence to Sequence模型叫做Encoder Decoder模型。
Sequence to Sequence用在AS… 更多... “ASR之Sequence to Sequence”
本篇是RNN-T的学习笔记,图片来源于
介绍RNN-T之前介绍一下RNA,因为它是介于上一篇介绍CTC和本篇要介绍的RNN-T之间的一个东西。RNA时候Recurrent Neural Aligner的缩写,
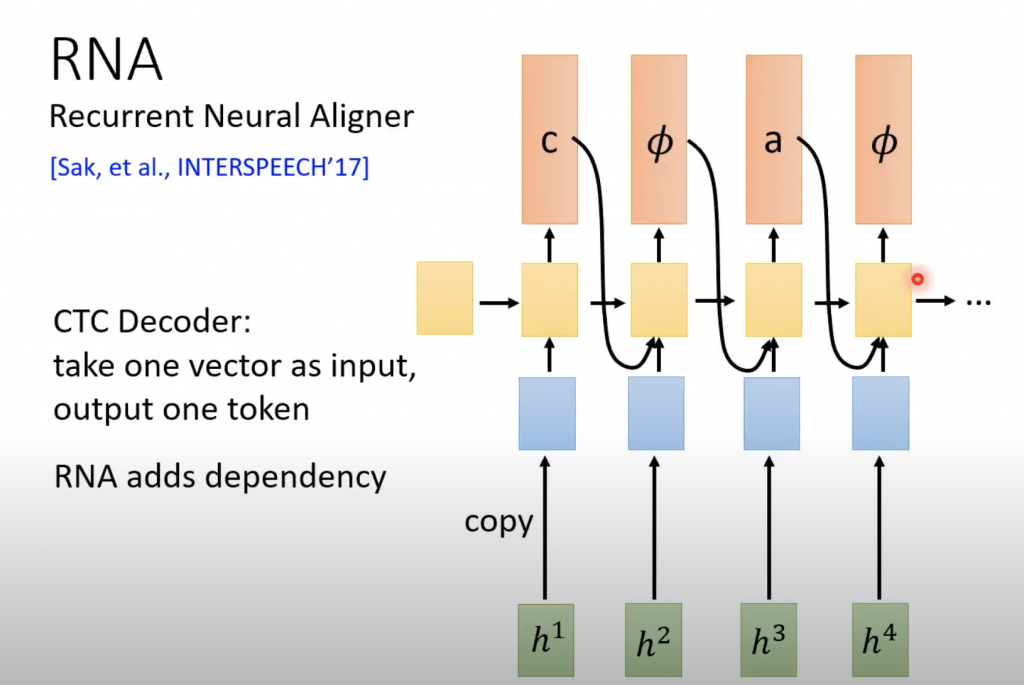
CTC每一个token输出的时候,是相互独立的,RNA就会让当前输出token的时候参看上一个输出的token,并且把linear的classifier改成RNN。
本片文章的图片来源于
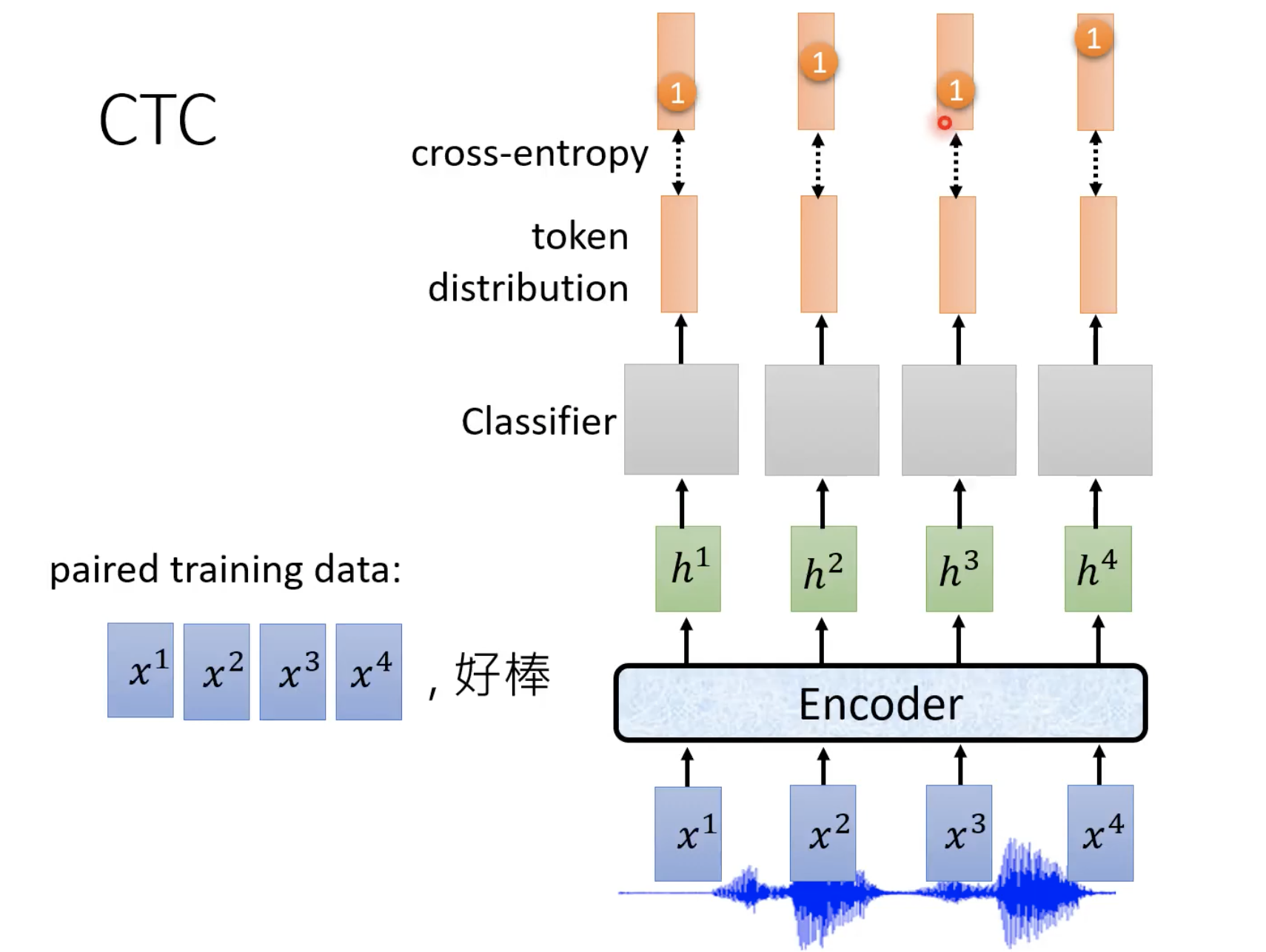
输入N个feature,输出N个token
当不知道该输出什么的时候,就输出∅
合并∅ 之间相同的token,然后去掉∅
例如
∅ccc∅aa∅∅
合并之后就是输出 cat
下面是CTC解码的过程
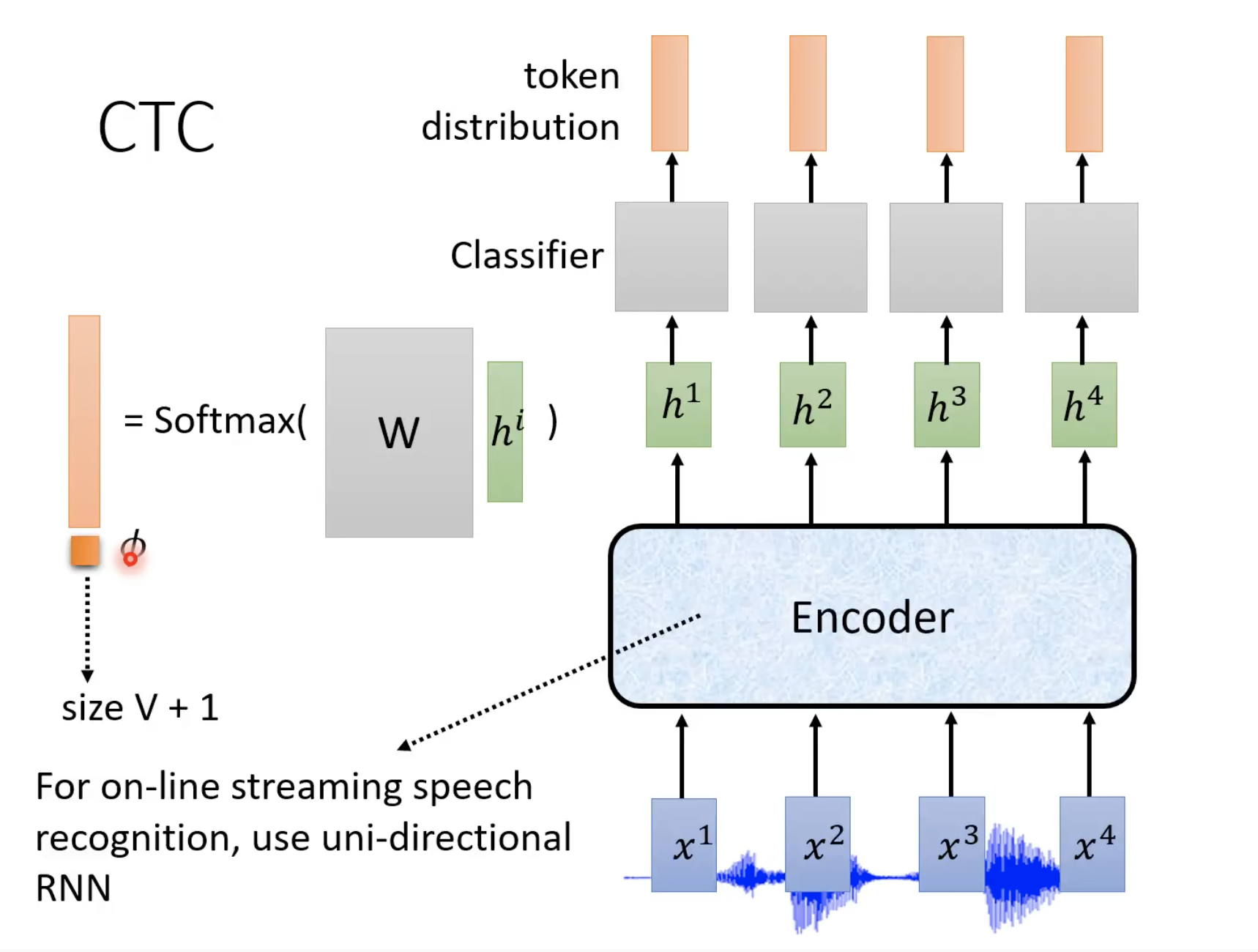
上面的classifier是linear classifier,token distribution表示输出哪个token的几率最大。