Kaldi之Lattice
在Decode时候,使用Viterbi算法可以得到最优的一条路径,但是往往它可能不是最好的,因此我们采用Beam Search得到一个几个路径,我们给定一个范围(Kaldi的命令参数使用的时候 –beam),距离最优路径一定范围的都留下来,于是会得到N best的结果

我们可以采用保存所有它走的路径,包括状态,ilabel,olabel,第几帧等信息。
那N best的时候,一般采用低阶的LM(一般是1-gram的LM)(这样可以快速的解码,否则HCLG太大,解码无法进行或者太慢),然后采用高阶的LM重打分得到最好的一个。
Lattice的类型
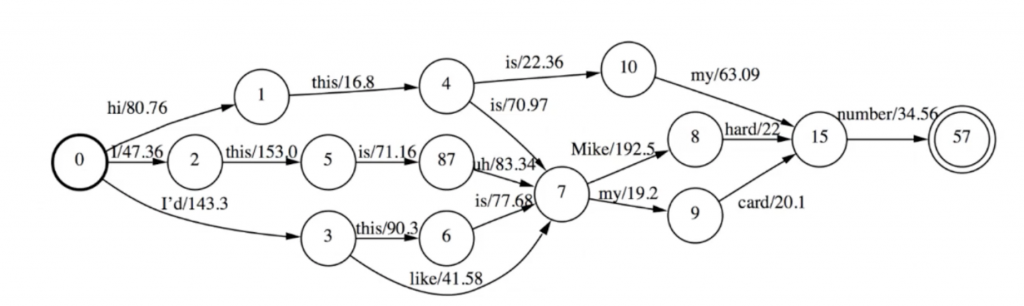
Kaldi中有Lattice和CompactLattice,是2种不同的存储形式,可以相互转化。在外观上和HCLG相似,都是有state和arc组成。
Lattice的arc: ilabel = transition-id, olabel=word-id,weight=(graph-cost,acoustic-cost)
CompactLattice的arc: ilabel=olabel=word-id, weight=(graph-cost,acoustic-cost,transition-id)
下面是简单的Lattic的FST的图
N-best lists and best paths
有些时候(e.g. Viterbi training;用神经网络语言模型重打分)我们不需要网格结构而是需要最佳路径或 N-best路径。N-best列表的格式和网格一样,除了每个句子有多个 FSTs(最多 n个,如果设定了 n)。假设 utterance ids是 uttA, uttB等。网格的一个 Table(e.g. an archive)会包含 uttA的网格,uttB的网格,等等。如果运行:
lattice-to-nbest –acoustic-scale=0.1 –n=10 ark:1.lats ark:1.nbest
那么 archive 1.nbest会包含网格 uttA-1, uttA-2,…uttA-10和 uttB-1…uttB-10等等。当然某些语句可能没有这么多的 N-best,因为网格没有那么多的不同的词序列。lattice-to-nbest需要 acoustic scale因为这影响到哪个路径得分最低。
某些情况下处理 FST还是不够方便,而我们需要一个线性结构,e.g. 一个词序列。这时,我们可以用:
nbest-to-linear ark:1.nbest ark:1.ali ark:1.words ark:1.lmscore ark:1.acscore
这个程序读网格的 archive,它必须是一个线性 FST,然后输出4个 archives,对应输入符号序列,输出符号序列,the acoustic and LM scores。格式会像下面一样(假定你以文本方式写):
$> head 1.words
utt-A-1 10243 432 436 10244
utt-A-2 7890 420 10244
…
Kaldi会处理后面的数字 id;你可以用符号表和 scripts/int2sym.pl把它们转换为词。上面的逆变换可以用linear-to-nbest完成。
更多lattice的细节请参看Kaldi Lattice或者中文版的Kaldi lattice