
ASR之Listen Attention Spell
本篇是关于学习LAS的笔记,图片来自这个视频,
和论文 Attention is All You Need。
Listen
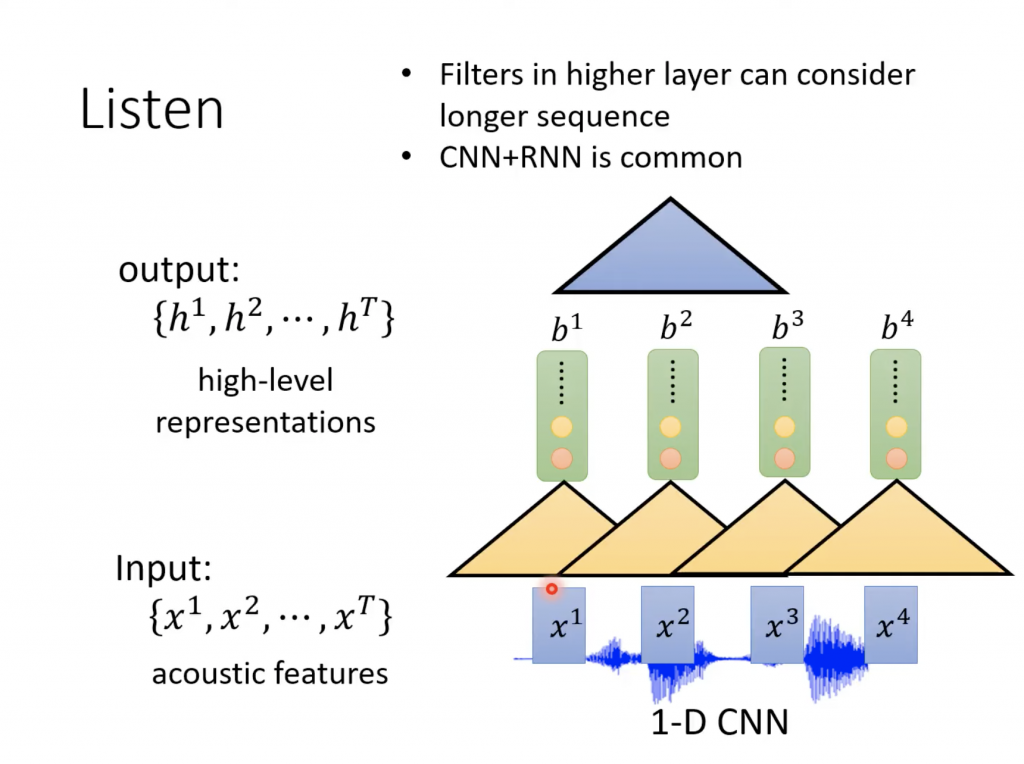
黄色的三角形代表的是filter,每次filter吃3个feature(一次吃几个feature,可以自定义),然后产生一个数字,三角形向右移动一个feature,然后再拿3个feature,做同样的事情。有很多个这这样的filter,这样就会产生同样多的新的一组向量,就是上面浅绿色的部分。
接下来可以再在上面叠加类似的filter,这个可以自己定义。
Attention
Attention相当于在一堆数据中,查询和关键相关的数据。在我们的ASR任务重,一堆数据就是一组feature,例如mfcc或者fbank。
Attention的数学化的表示如下,
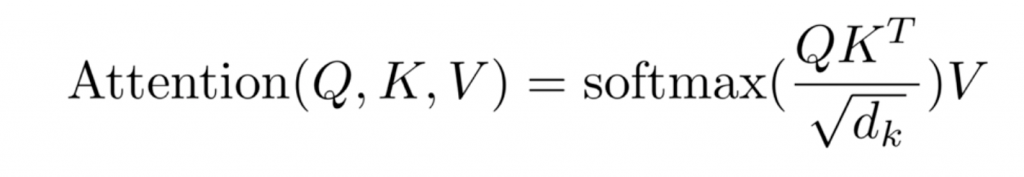
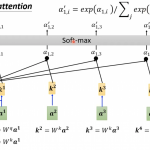
Attention的图形化的表示如下,
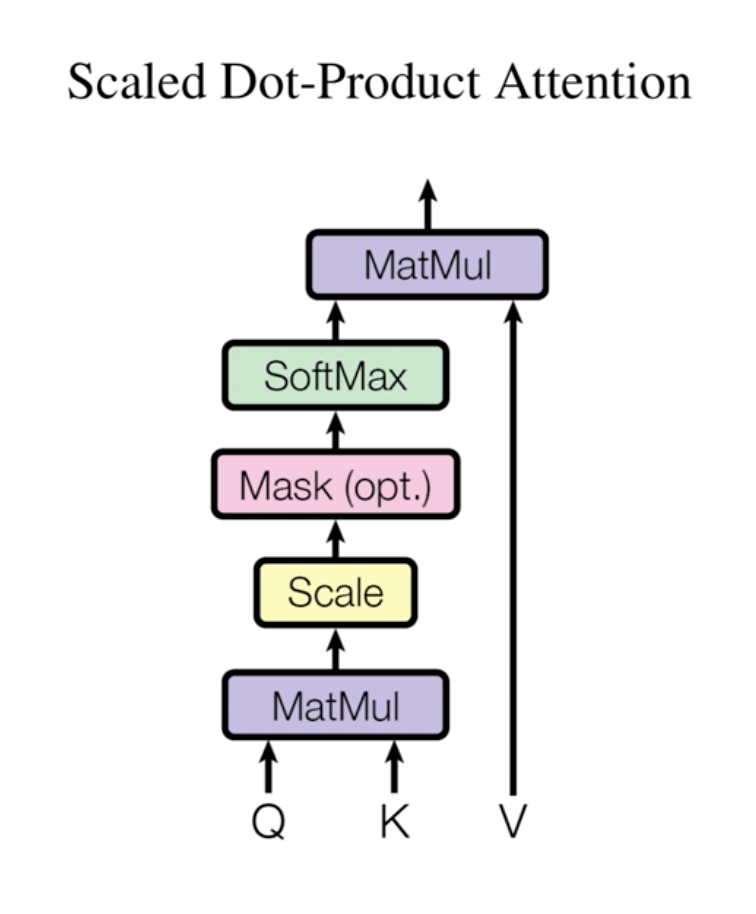
上图中mask一步是可选的。
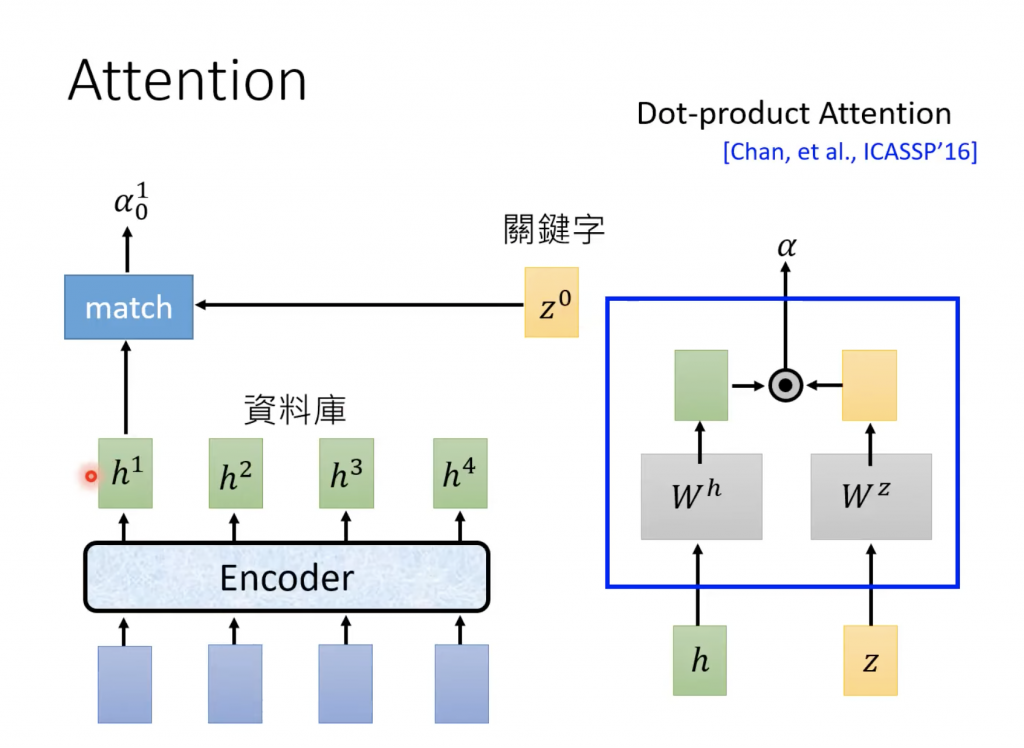
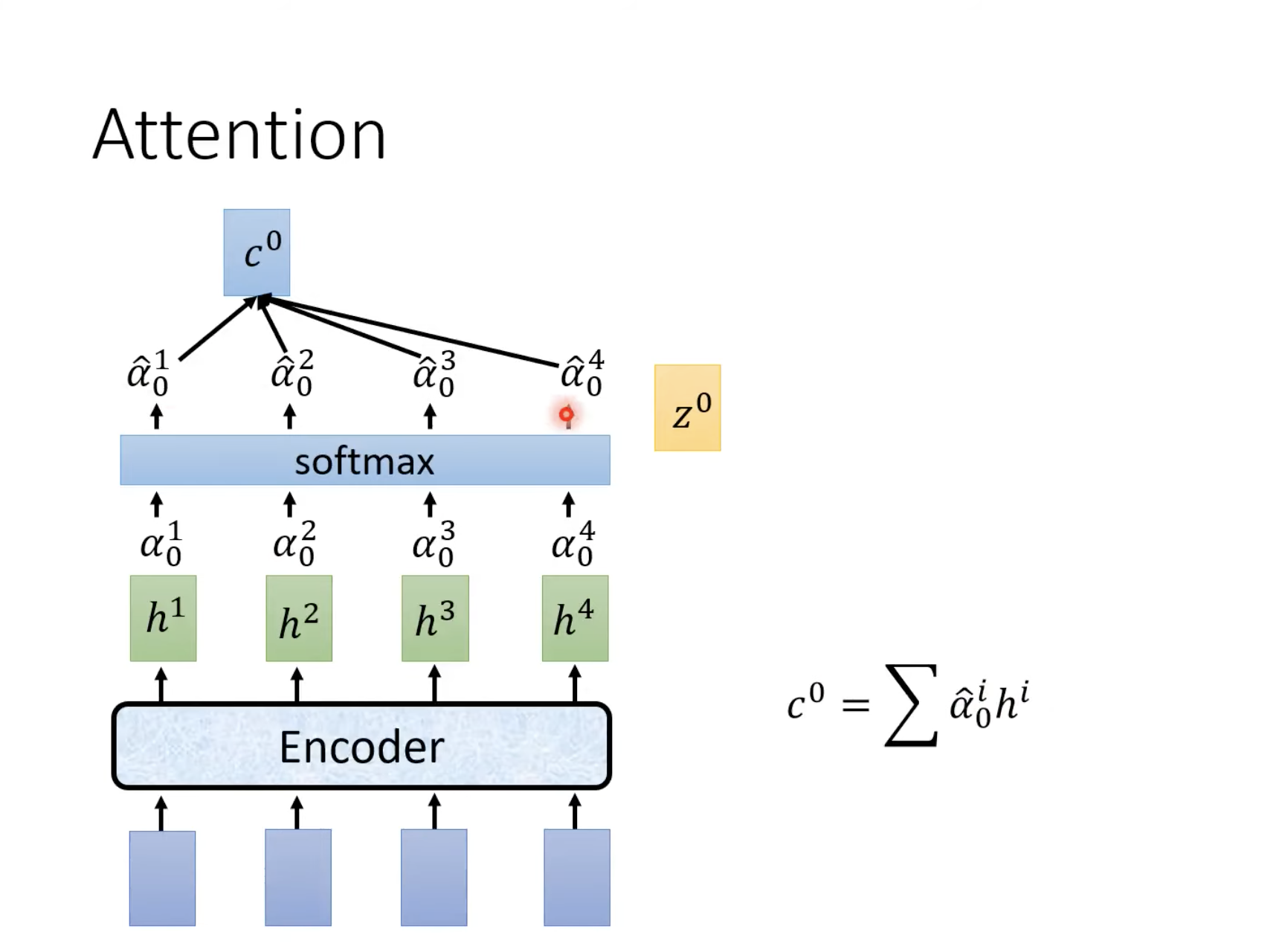
上图中h就是Listen图中的b向量。上图中下面一层的α是通过下面的点乘(dot product)实现
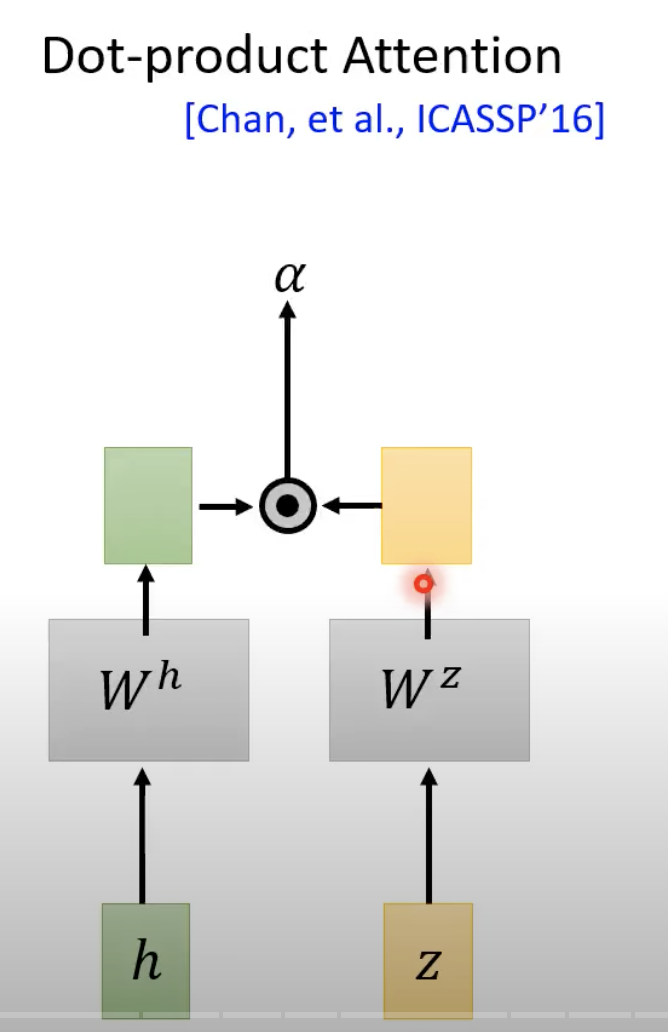
z0是一个初始化向量,Wh和Wz是2个矩阵(相当于2个超参数),经过这2个矩阵的transform之后再进行点乘就得到α。这个操作其实就是计算z0和h0这2个向量的相似度。除了上面的这种点乘方式外,还有一个下面的Additive Attention
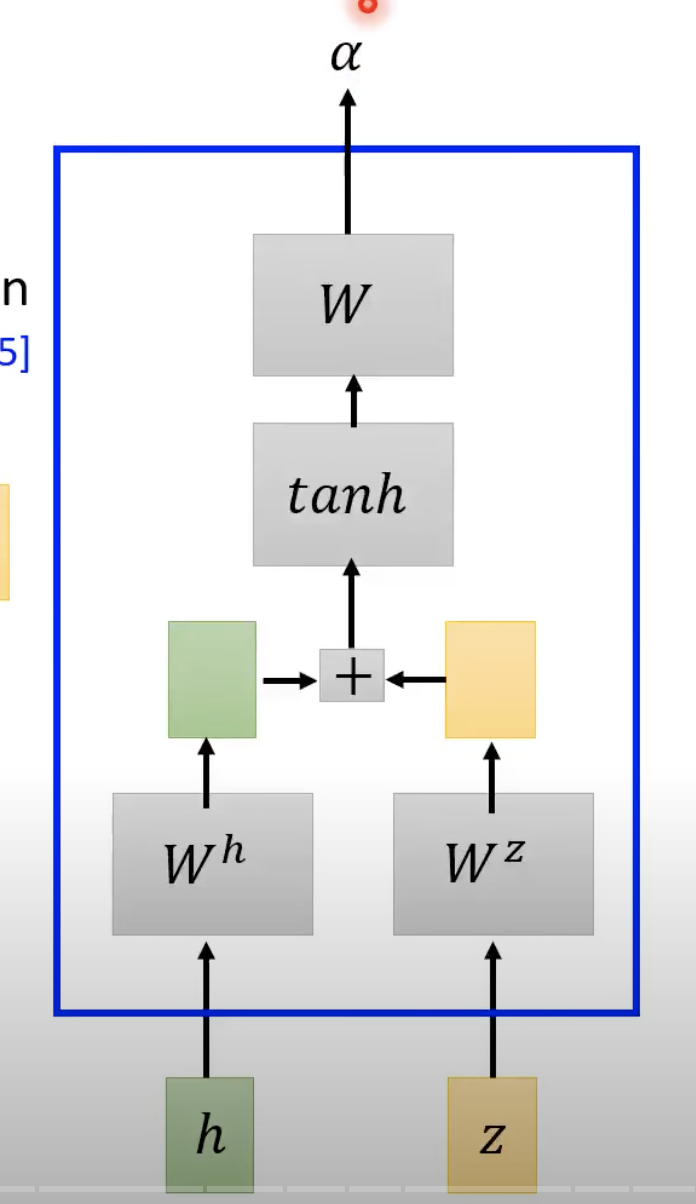
上图中W是向量,之后进行linear transform,将W转换为一个标量(scalar)。
之后经过softmax做归一化得到上层的α。这些α的值也被称为attention score。之后将这些α乘到下面的feature向量,然后再加和得到c。
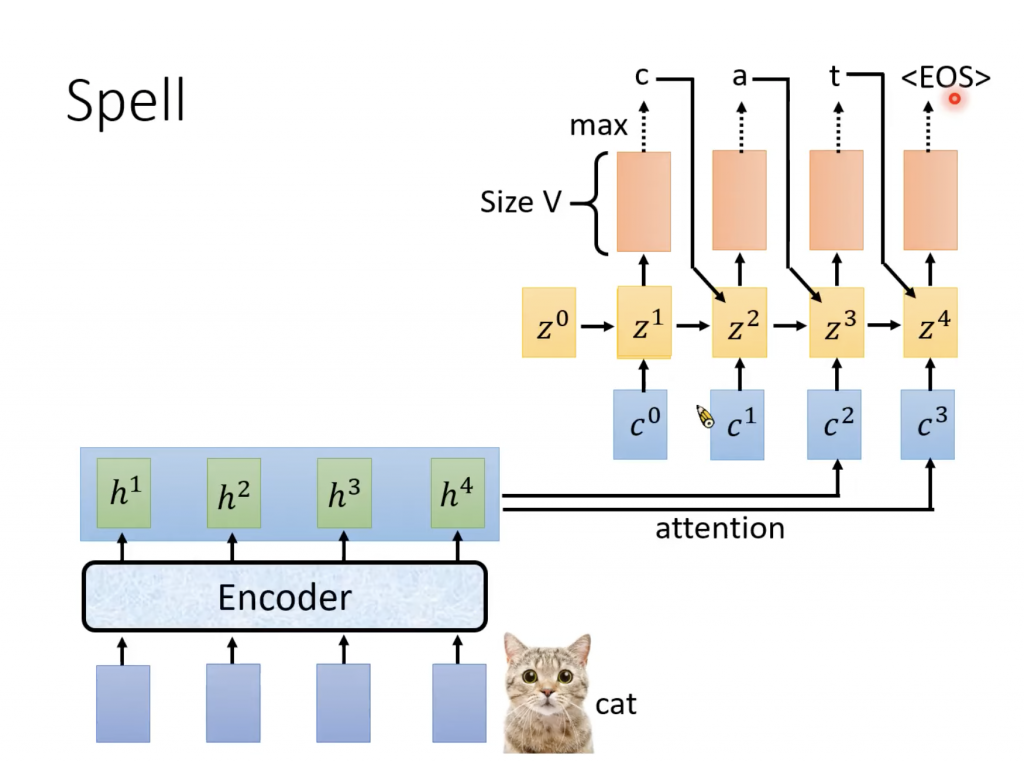
Spell
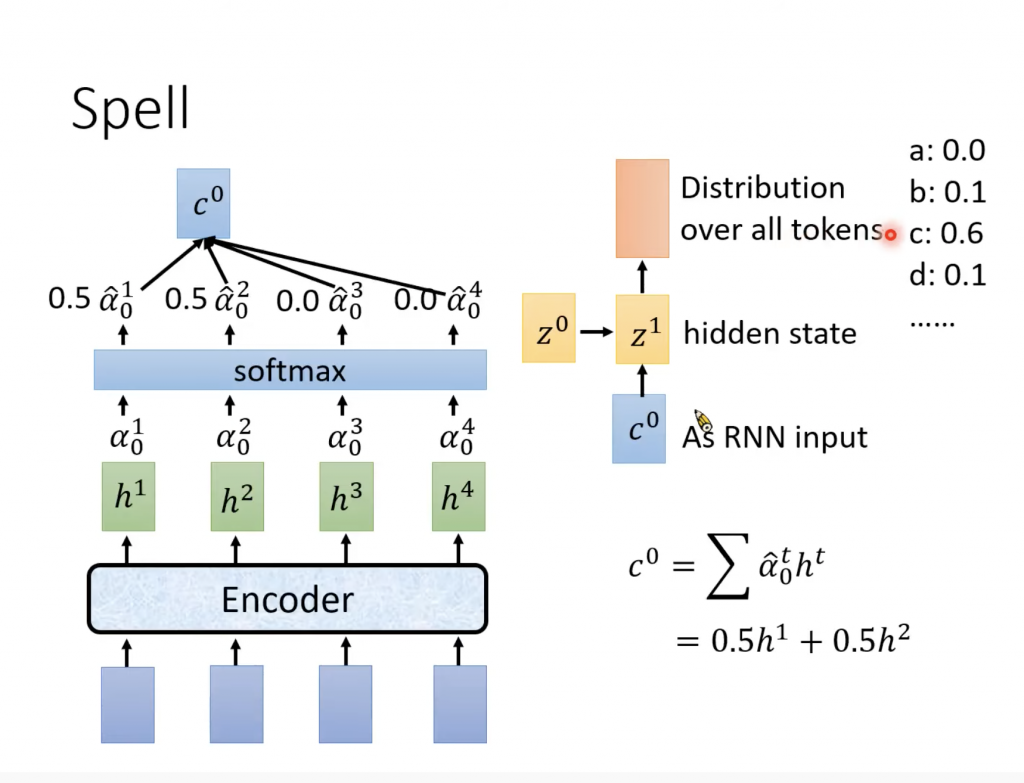
Attention得到的C会作为RNN的input,然后输出Z,之后进行transform得到distribution,这个distribution就是我们所选择的每个token的几率。Token是我们自己定义的,可以phonime,morphonime,字(比如中文)或者词(比如英文),几率最大的那个token就作为输出,也就是我们识别出了一个token。接下来使用生成的z1和h做attention部分是事情得到C1,这次我们会把前面得到的token作为一个输入,所以新的输入会有C1和token,然后spell得到新的z2和token,这样有新的Z就产生新的C,又输出一个token,一直持续下去,直到输出EOS(end of sentence),表示对于这一组输入向量,我们已经输出了所有的token。
Training
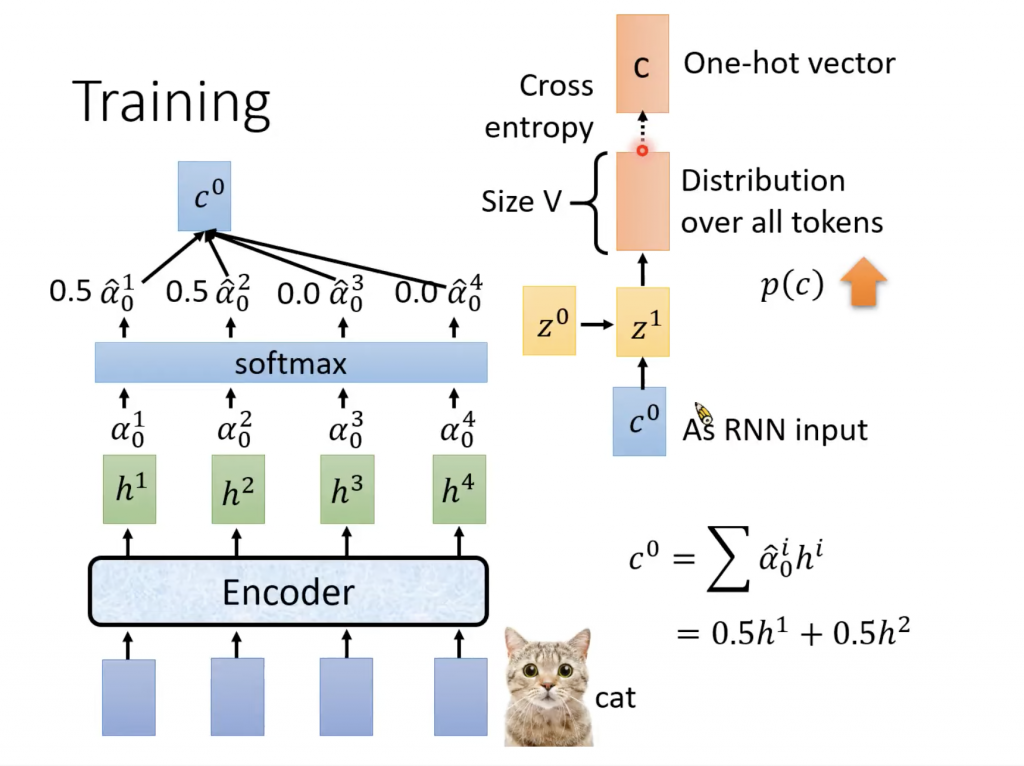
介绍了上面的解码部分,training的部分就是在计算出distribution之后计算它和ground truth的距离,ground truth就是one hot vector,真实的token所在那一维为1,其余全部分为0.计算的方法就是Cross Entropy。
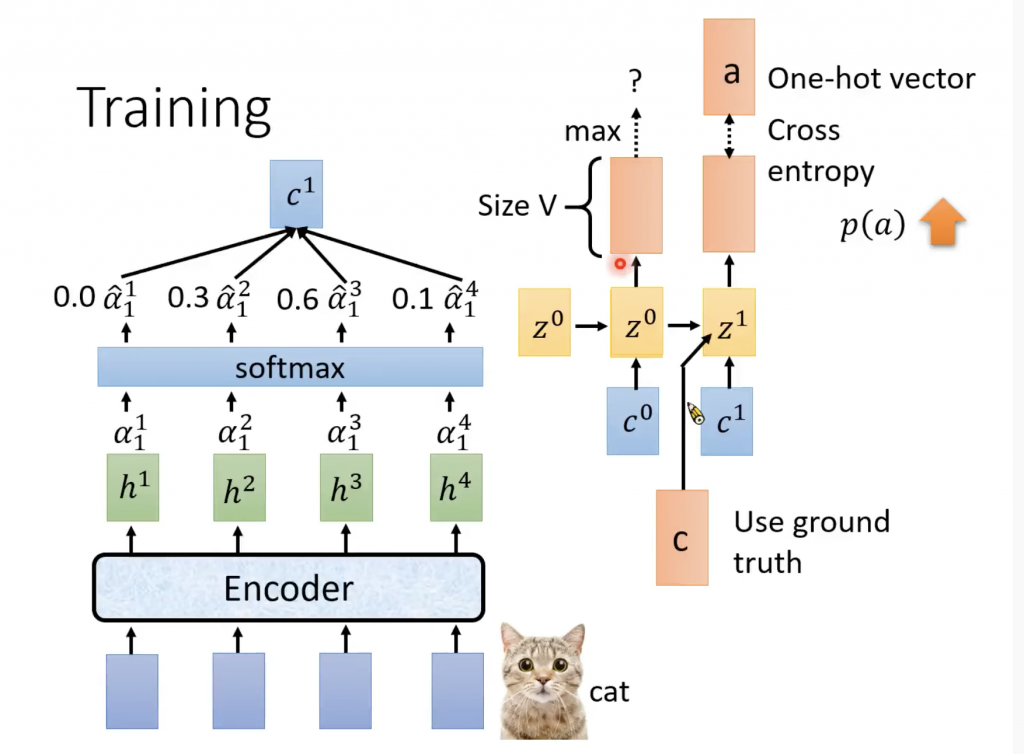
上面提到在spell的时候,输出第二个distribution的时候,要参考第一distribution的token,那我们training也是真么做吗?不是,为什么?如果训练的时候,token是错误的(通常一开始是一个随机的值),我们使用这个错误的token,那么RNN训练的结果全部时候错误。为了解决这个问题,我们直接使用正确的token,而不是前面的输出的token。
LAS的应用
上面说的是使用LAS做基本的语音识别,比如输入英语的一段语音,输出对应的英文。LAS是基于的sequence to sequence的model,所以我们可以属于一段语音信号,输出一个sequence,这个sequence可以是中文,这样变成一个语音翻译系统。
还或者属于一段语音,输出一段另外一种语言的语音,比如输入英文语音输出中文语音。
LAS的缺点
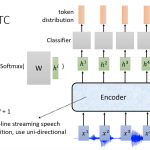
从上面可以看到我们基于一组feature向量(一段语音),然后识别(spell),所以不可以每个feature进去输出一个token。要做到输入一个feature得到一个token,CTC,RNN-T可以做到,当然包括传统的语音识别框架。
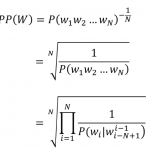
4 Replies to “ASR之Listen Attention Spell”