提取流程
- UBM
universal background model[1]
使用GMM建模,UBM的训练通过EM算法完成,有两种方法:
• 所有的数据训练出来一个UBM,需要保证训练数据的均衡
• 训练多个UBM,然后合在一起,比如根据性别分成两个,这样的话可以更有效的利用非均衡数据以及控制最后的UBM。 - supervector
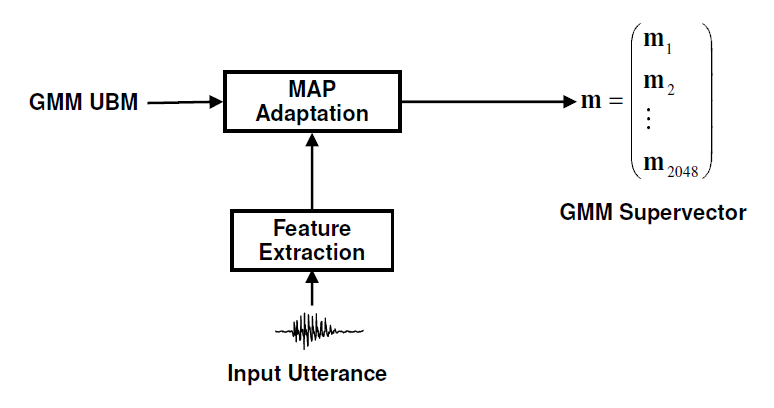
使用MAP adaptation对UBM的高斯进行线性插值,获得speaker相关的GMM模型,该模型的均值作为supervector[2]。详细的训练过程参考[1].
假设UBM有C个分量,特征维度为F,那么最后得到的supervector的维度为C*F
- ivector
identity vector
s=m+Tw
s: supervector
m: ubm’s mean supervector
T: total-vavriability matrix
w: i-vector
s和 m前两部分已经获得,为了获得最后的 w,只剩下获得 T。
使用EM算法可以获得最后的 T[3].
- LDA PLDA
ivector同时包含speaker和channel的信息,使用LDA和WCCN来减弱channel影响。
Kaldi实现
1.UBM
universal background model 使用gmm来刻画
UBM训练流程,最后得到final.dubm:
steps/online/nnet2/train_diag_ubm.sh
#gmm-global-init-from-feats 根据所有特征训练gmm
#gmm-gselect gmm-global-acc-stats 获取gmm训练的统计量
#gmm-global-est 根据统计量重新训练gmm
#gmm-global-copy 转化final.dubm为文本形式
12345
假设特征40维,高斯个数为512
2.extractor
ivector模型用来提取100维ivector特征,和mfcc特征合在一起当做dnn的输入,最后生成的模型是final.ie,训练流程如下
steps/online/nnet2/train_ivector_extractor.sh
#ivector-extractor-init 使用final.dubm初始化最开始的ivector
#gmm-global-get-post 根据final.dubm获取cmvn后的特征的后验概率
#ivector-extractor-sum-accs 获取统计量
#ivector-extractor-est 根据统计量获得最后ivector模型final.ie
ivector-extractor-init –binary=false –ivector-dim=100 –use-weights=false “gmm-global-to-fgmm final.dubm -|” txt #查看文本形式的ie
1234567
由于 s s s的维度是51240, m m m的维度也是51240, w w w的维度是100,所以最后得到的 T T T的维度为51210040
3.提取ivector
ivector可以每一句一个,online的形式可以设成10帧一个,需要的文件包括:
–cmvn-config=run/run_chain_1000h_pitch/exp/ivectors/train_max2/conf/online_cmvn.conf
–ivector-period=10
–splice-config=run/run_chain_1000h_pitch/exp/ivectors/train_max2/conf/splice.conf
–lda-matrix=run/run_chain_1000h_pitch/exp/extractor/final.mat
–global-cmvn-stats=run/run_chain_1000h_pitch/exp/extractor/global_cmvn.stats
–diag-ubm=run/run_chain_1000h_pitch/exp/extractor/final.dubm
–ivector-extractor=run/run_chain_1000h_pitch/exp/extractor/final.ie
–num-gselect=5
–min-post=0.025
–posterior-scale=0.1
–max-remembered-frames=1000
–max-count=0
123456789101112
ivector提取流程如下:
steps/online/nnet2/extract_ivectors_online.sh
#1.特征处理:cmvn+splice+lda
#2.根据特征和m(final.dubm)获得每个speaker对应的s
#3.根据s、m(final.dubm)、T(final.ie)得到w
#查看ivector特征
copy-feats –binary=false –compress=false ark:ivector_online.1.ark ark,t:ivector_online.1.ark.txt
1234567
训练和解码的文件需要保持一致,不然结果会差距比较大。
参考文献
[1].Speaker Verification Using Adapted Gaussian Mixture Models
[2].Support Vector Machines using GMM Supervectors for Speaker Verification
[3].Implementation of the Standard I-vector System for the Kaldi Speech Recognition Toolkit
本文摘自:
https://blog.csdn.net/xmdxcsj/article/details/78512620